Related Books





Books / Object-Oriented Reengineering Patterns / Chapter 7
Migration Strategies
In this chapter
- Forces
- Overview
- 7.1 Involve the Users
- 7.2 Build Confidence
- 7.3 Migrate Systems Incrementally
- 7.4 Prototype the Target Solution
- 7.5 Always Have a Running Version
- 7.6 Regression Test After Every Change
- 7.7 Make a Bridge to the New Town
- 7.8 Present the Right Interface
- 7.9 Distinguish Public from Published Interface
- 7.10 Deprecate Obsolete Interfaces
- 7.11 Conserve Familiarity
- 7.12 Use Profiler Before Optimizing
Your re-engineering project is well underway. You have developed a good understanding of the legacy system and you have started to Write Tests to Enable Evolution [p. 139]. You have gone through a process of Setting Direction and have decided to tackle the Most Valuable First [p. 25].
How can you be sure that the new system will be accepted by users? How do you migrate to the new system while the old system is being used? How can you test and evaluate the new system before it is finished?
Forces
-
Big-bang migration carries a high risk of failure.
-
Introducing too many changes at once may alienate users.
-
Constant feedback helps you stay on track, though it may be difficult and costly to achieve.
-
Users have to get their work done; they don’t want to be distracted by incomplete solution.
-
Legacy data must survive while the system is being used.
Overview
It is not enough to reengineer a legacy system and then deploy it. In fact, if you try this, you will surely fail (for the same reasons that big Waterfall projects in new territories often fail). You must be prepared to introduce the new solution gradually, to gain the confidence and collaboration.
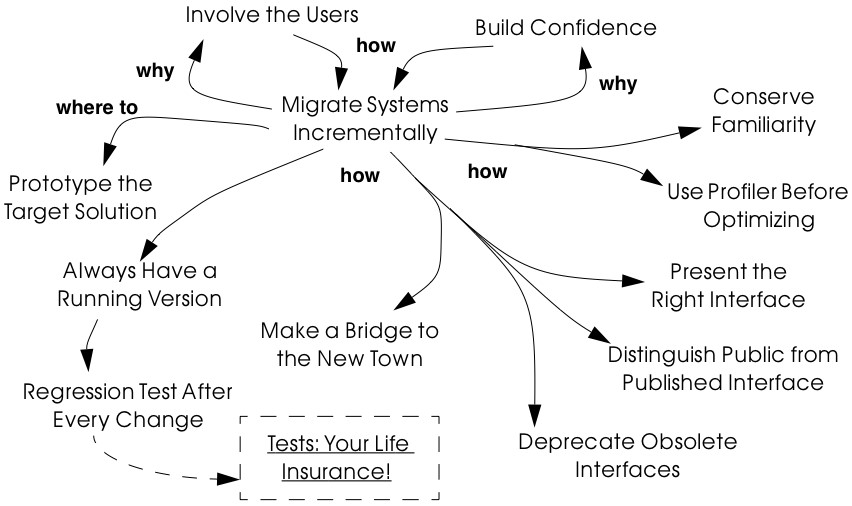
Figure 7.1: How, why and whither to migrate legacy systems. of the users, and you must adopt a strategy for migrating gradually and painlessly from the existing system, while it is still being deployed, to the new system.
The central message of this cluster is to Migrate Systems Incrementally. This is, however, easier said than done. In figure 25 we can see that in order to Migrate Systems Incrementally, we should consider a large number of other patterns. Since there exists a vast literature on system migration, we do not attempt to cover the topic in great detail. We have selected, however, the patterns that we consider to be most important for re-engineering object-oriented legacy systems, and summarized the main points. Where appropriate, we point the reader to further sources of information.
Although the central pattern of this cluster is Migrate Systems Incrementally, the key motivation is provided by Involve the Users and Build Confidence. These first three patterns are fundamental patterns for minimizing risk and increasing the chances of success:
-
Involve the Users increases the chance that users will accept the new system by involving them closely in the entire re-engineering process, getting them to use intermediate results, and providing them with strong support. It is easier to achieve if you Migrate Systems Incrementally and Build Confidence step by step.
-
Build Confidence helps you overcome skepticism and doubt by regularly delivering results that are of value to the users.
-
Migrate Systems Incrementally recommends that the old system be gradually and incrementally replaced by the new system. New results can then be integrated as you proceed, thus helping you to Build Confidence and Involve the Users.
It is very hard to Migrate Systems Incrementally unless you also adhere to the following practices:
-
Prototype the Target Solution to test the new architecture and new technical risks. It is too easy to be tempted to think you don’t need a prototype since you already have a running system, but this is almost always a mistake.
-
Always Have a Running Version helps to keep changes in sync by ensuring that they are integrated frequently.
-
Regression Test After Every Change helps to you Always Have a Running Version by making sure that everything that used to run still runs. It presupposes that you Write Tests to Enable Evolution [p. 139].
Depending on the circumstances, there are various practices that may help you to Migrate Systems Incrementally:
-
Make a Bridge to the New Town introduces the metaphor of a (data) “bridge” to allow you to gradually migrate data from a legacy component to its replacement, while the two run in tandem. When all the data have been transferred, the legacy component can be retired.
-
Present the Right Interface helps you to develop the target system in increments by wrapping the old functionality to export the abstractions you really want.
-
Distinguish Public from Published Interface distinguishes between stable (public) and unstable (published) interfaces to facilitate parallel development within a re-engineering team.
-
Deprecate Obsolete Interfaces lets you gracefully retire obsolete interfaces without immediately invalidating clients.
Finally, the following two practices may help you avoid making radical, but unnecessary changes:
-
Conserve Familiarity warns you against introducing radical interface changes that may alienate users.
-
Use Profiler Before Optimizing [p. 198] reminds you to delay considering performance issues until you can demonstrate that you have a problem and can pinpoint the source of the problem.
7.1 Involve the Users
Also Known As: Engage Customers [Cop95]
Intent Maximize acceptance of changes by involving the users at every step.
Problem
How can you be sure that users will accept the reengineered system?
This problem is difficult because:
-
The old systems works. It is clunky, but the users know how it works and know how to get around the problems.
-
People hate to have to learn something new unless it really makes their life simpler.
-
User perceptions of what is needed to improve a system tend to change as the system evolves.
-
Users can have difficulty evaluating a paper design.
-
It is hard to get excited about a new system that is not ready to use.
Yet, solving this problem is feasible because:
-
Users will try new solutions if they see that their needs are being seriously addressed.
-
Users will give you feedback if you give them something useful to use.
Solution
Get the users directly involved in the new development, and support them closely in using the new system.
Steps
Get the users to tell you where their priorities lie. Start with Most Valuable First [p. 25]. Break the priorities down into small steps that can be delivered in regular increments, so you can Build Confidence [p. 172].
Create an environment that will encourage contact between users and developers. Physical location is important.
Establish simple procedures for delivering intermediate results on a regular basis and obtaining feedback. Early prototypes may help, especially to evaluate risky new technologies or approaches. A good strategy is to Migrate Systems Incrementally [p. 174] so that users can start using the new system as it is being built. You should Conserve Familiarity [p. 196] to avoid alienating users.
Tradeoffs
Pros
-
Requirements will continuously be validated and updated, increasing your chances that you will move in the right direction.
-
If the users feel they are getting useful results and they are being supported, they will put extra effort into giving useful feedback.
-
Users will be involved throughout the effort, eliminating the need for a special training session late in the project.
Cons
-
Developers may feel that supporting users is distracting them from the job of re-engineering the system.
-
If you succeed in involving the users, this will raise expectations and put extra pressure on your team. For instance, Your don mentions that prototypes can really raise expectations too much and that you should always make clear which parts are not yet working [You97].
Difficulties
-
It can be hard to involve the users initially, before you have shown any results.
-
You can’t involve everybody, and the users who are left out might feel neglected.
Rationale
You need a feedback loop to ensure that you are addressing the real customer needs. By involving and supporting the users, you encourage this feedback loop.
Coplien points out: “Note that ‘maintaining product quality’ is not the problem being solved here. Product quality is only one component of customer satisfaction.” [Cop95]
Related Patterns
Virtually all of the patterns in this cluster support Involve the Users. Migrate Systems Incrementally to get the users working with the system as it is being reengineered and thereby Build Confidence.
The Planning Game [BF01] is an effective technique to Involve the Users by iteratively identifying stories, estimating costs, and committing to the stories to be released.
7.2 Build Confidence
Intent Improve your chances of overall success by demonstrating results in regular increments.
Problem
How can you overcome the high degree of skepticism that customers and team members often have for any kind of software project?
This problem is difficult because:
-
Few software projects meet requirements, come in on time, and stay within budget. The skepticism that accompanies most projects can easily lead to defeatism, and projects can fail as a self-fulfilling prophecy.
-
Users rarely get what they really want or need.
-
It can be hard to convince either the users or even your own team that the legacy system can really be salvaged.
Yet, solving this problem is feasible because:
- You don’t need to solve all the problems at once.
Solution
Create a positive atmosphere by demonstrating some positive results as early as you can, and continue to do so on a regular basis.
Steps
Pick short intervals for delivering new results. At each step, try to agree together with the users what are the smallest results that can demonstrate real value.
Tradeoffs
Pros
-
Both users and developers can measure real progress.
-
It is easier to estimate the cost of smaller steps.
Cons
-
It takes time to frequently synchronize with the users.
-
Users may resent the extra work it takes to use the new system in tandem with the old one.
-
If you succeed to demonstrate good results early in the project, you may raise expectations too high.
Difficulties
-
Some requirements can be hard to break down into small steps, particularly if they entail architectural changes to the system.
-
Reengineering teams must be careful not to alienate the developers of the original system, since they are one of the most valuable sources of information.
-
It is not enough to convince users — you must also take care to get commitment from management. It is hard to convince management in small steps. Plan big demos at regular intervals.
Rationale
By taking smaller steps, you reduce the risk that an individual step will fail. Frequent, positive results help to build confidence. By the same token, Extreme Programming advocates Small Releases [Bec00]. Even negative results help you to monitor progress and understand better the situation, and so help to build up confidence.
Related Patterns
Prototype the Target Solution and Make a Bridge to the New Town can make it easier to demonstrate results in small steps.
It is easier to Build Confidence if you Involve the Users.
7.3 Migrate Systems Incrementally
Also Known As: Chicken Little [BS95]
Intent Avoid complexity and risk of big-bang re-engineering by deploying functionality in frequent increments.
Problem
When should you plan to deploy the new system?
This problem is difficult because:
-
Projects are often planned and funded on large time scales, with “big bang” requirements specification done up front.
-
The real requirements are often only clear in hindsight. Users will resist adopting a new system that is radically different from what they are used to, especially if it does not work flawlessly from the beginning.
-
The longer you wait to deploy the new system, the longer you must wait to get user feedback.
-
You cannot deploy an incomplete system. Users do not have time to waste on incomplete solutions.
Yet, solving this problem is feasible because:
- You have a running system that can be extended and modified.
Solution
Deploy a first update of the legacy system as soon as you can, and migrate incrementally to the target system.
Steps
-
Decompose the legacy system into parts.
-
Choose one part to tackle at a time.
-
Put tests in place for that part and the parts that depend on it.
-
Take appropriate steps to wrap, reengineer or replace the legacy component.
-
Deploy the updated component and obtain feedback.
-
Iterate.
Tradeoffs
Pros
-
You get user feedback early and Build Confidence.
-
You see immediately when things break.
-
Users learn the new system as it’s being built.
-
The system is always deployed.
-
The system is always being tested, so you can’t skip testing.
Cons
- You will have to work harder to keep the system running while you are changing it.
Difficulties
-
It can be difficult to migrate to a new architecture. You may want to Prototype the Target Solution to get the new architecture in place, and Present the Right Interface to the old system to hide the legacy interfaces while you migrate the underlying components.
-
It is risky to change a running system. Be sure to Regression Test After Every Change.
Rationale
You get the best user feedback from a running system. Users are more motivated and involved with a system they use daily.
Known Uses
Migrating Legacy Systems [BS95] introduces this pattern under the name “Chicken Little” (to migrate incrementally means to “take Chicken Little steps”). This book discusses in great detail strategies and techniques for incremental migration.
Related Patterns
Apply Most Valuable First [p. 25] to select the legacy components to work on first. Appoint a Navigator [p. 23] to maintain architectural integrity.
Write Tests to Enable Evolution [p. 139], and Grow Your Test Base Incrementally [p. 144] as you migrate. Be sure to Test the Interface, Not the Implementation [p. 155] so you do not always have to rewrite your tests as you reengineer or replace legacy components. Regression Test After Every Change [p. 182] so you can Always Have a Running Version [p. 180].
Consider applying Present the Right Interface for legacy components that you do not intend to reengineer or replace.
You might consider to Make a Bridge to the New Town [p. 184] if you need to migrate data from legacy components that you are replacing.
7.4 Prototype the Target Solution
Intent Evaluate the risk of migrating to a new target solution by building a prototype.
Problem
How do you know if your ideas for the new target system will work?
This problem is difficult because:
-
It is risky to make radical changes to a working system.
-
It can be hard to anticipate how design changes will impact existing functionality.
-
A solution that works is more believable than one that one that has not been tested.
Yet, solving this problem is feasible because:
- You don’t need to reengineer the whole legacy system to test the new ideas.
Solution
Develop a prototype of the new concept and evaluate it with respect to the new, emerging requirements.
Steps
-
Identify the biggest technical risks for your re-engineering project. Typically they will concern things like:
-
choice of a new system architecture
-
migration of legacy data to new system
-
adequate performance — or performance gains — with new technology or platform (for example, demonstrating that a certain transaction throughput can be achieved)
-
-
Decide whether to implement an exploratory (i.e., throwaway) prototype that will service purely to evaluate the feasibility of a technical option, or rather an evolutionary prototype that will eventually evolve into the new target system.
-
An exploratory prototype must be designed to answer very precise questions. These may be purely technical questions, such as whether the new platform can meet performance constraints set by the legacy system, or they may be usability questions which require participation of and evaluation by the users. The exploratory prototype does not need to be designed to address any other issues or questions, and will not be part of the migrated system (although the answers it provides will influence the new system).
-
An evolutionary prototype, on the other hand, is intended to eventually replace a legacy component, and must therefore reflect the target architecture. The new architecture most not only adequately support the legacy services, but also overcome the obstacles that limit the legacy solution’s usefulness. The prototype must be design to answer these risks first.
-
Tradeoffs
Pros
-
A prototype can be built quickly, since it does not have to implement all the functionality of the legacy system.
-
You can hack parts of the legacy system to get your prototype running.
-
You can learn quickly if your ideas for the target system are sound.
Cons
-
Users may not be highly motivated to spend a lot of time evaluating a throwaway prototype.
-
You may be tempted to continue to develop the throwaway prototype.
Difficulties
-
It may be hard to convince yourself or your customer of the need for a prototype — after all, you already have a running system.
-
It can take too much time to get an evolutionary prototype up to speed. Consider applying Present the Right Interface to legacy components to provide a good interface for legacy services to the prototype.
Rationale
A prototype can tell you quickly whether a certain technical approach is sound or not. Brooks in The Mythical Man-Month [Bro75] advises us to “write one to throw away” since it is hard to get it right the first time.
Love [Lov93] takes this one step further and warns us that, for object oriented systems we should “write two to throw away”! Foote and Yoder [FY00] argue that, among other things, Throwaway Code is often the best way to clarify domain requirements, but they also warn that a prototype risks evolving into a “Big Ball of Mud”.
Related Patterns
You might consider applying Make a Bridge to the New Town to migrate legacy data to an evolutionary prototype.
7.5 Always Have a Running Version
Intent Increase confidence in changes by regularly rebuilding the system.
Problem
How do you convince your customer that you are on the right path?
This problem is difficult because:
-
It can be hard to demo a software system under development, or to discuss problems with users since there is often no stable, running version of the system available.
-
Integrating changes from multiple versions of a system can be slow and painful.
Yet, solving this problem is feasible because:
- You don’t have to wait until a component is “finished” before integrating it.
Solution
Institute a discipline of integrating new changes and developments on a daily basis.
Steps
-
Have version management and configuration management systems in place.
-
Make sure you have regression tests in place for the parts you are working on.
-
Institute a discipline of short transactions for checking out system components and checking them back in again. Plan iterations to be as short as possible to allow changes to be integrated into a running system.
Tradeoffs
Pros
-
You always have a working version to demo.
-
You can always have a working version to run your regression tests.
-
You can quickly validate your changes, thereby helping you to Build Confidence.
Cons
- You must continuously integrate changes.
Difficulties
-
Large systems may have very long build times. You may need to rearchitect the system first to enable shorter build times.
-
It can be hard to break some kinds of large modifications into meaningful updates that can be individually integrated.
Rationale
Many practitioners advocate a process of continuous integration as a way to avoid a risky and painful big-bang integration [Boo94].
Related Patterns
Regression Test After Every Change minimizes the risk of defects creeping in during integration.
Continuous Integration [Boo94] [Bec00] is a proven way to Always Have a Running Version.
7.6 Regression Test After Every Change
Intent Build confidence by making sure that whatever worked before still works.
Problem
How can you be sure that the last change you made won’t break the system?
This problem is difficult because:
- In a complex system, small changes can have unexpected side effects. A seemingly innocuous change may break something without this being immediately discovered.
Yet, solving this problem is feasible because:
- You have written test suites that express how the system should behave.
Solution
Run your regression test suite every time you think you have reached a stable state.
Tradeoffs
Pros
-
It is easier to Always Have a Running Version.
-
It is easier to Build Confidence as you proceed.
Cons
- You must relentlessly write the tests.
Difficulties
-
The legacy system may not have adequate regression tests defined. To enable evolution, you will have to Grow Your Test Base Incrementally [p. 144]
-
Tests can only show that defects are present, not that they are absent. You may have failed to test precisely the aspect that you have broken.
-
Run the tests may be very time-consuming, so you might want to run only those tests that you think might be affected by your change. Categorize your tests to avoid “ad hoc” testing of changes, but run all the tests at least once a day.
Rationale
Regression tests tell you that whatever ran before still runs. If you consistently build up tests for defects you discover and new features, you will end up with a reusable test base that gives you confidence that your changes are sound, and helps you detect problems earlier.
Davis advocates “Regression Test After Every Change” [Dav95] as standard Software Development practice.
Related Patterns
You should have already started to Write Tests to Enable Evolution [p. 139].
A common practice in Extreme Programming is to write tests before you implement new functionality [JAH01]. In the context of re-engineering, you should consider writing tests that will fail before you make a change, and will pass if the change is correctly implemented. (Unfortunately it is not generally possible to design tests that will only pass if the change is correct!)
Regression tests should help you to Retest Persistent Problems [p. 290].
7.7 Make a Bridge to the New Town
Also Known As: The Bridge to the New Town [Kel00], Keep the Data — Toss the Code [BS95]
Intent Migrate data from a legacy system by running the new system in parallel, with a bridge in between.
Problem
How do you incrementally migrate data from a legacy system to its replacement while the two systems are running in tandem?
This problem is difficult because:
-
Some components of the legacy system are beyond repair and should be replaced.
-
Big-bang replacement of critical components is highly risky.
-
The data manipulated by the legacy components must be kept available and alive during the migration.
Yet, solving this problem is feasible because:
- You have a running legacy system.
Solution
Make a (data) bridge that will incrementally transfer data from the legacy system to the replacement system as new components are ready to take the data over from their legacy counterparts.
Steps
-
Identify legacy and replacement components that deal with the same logical data entities.
-
Implement a “data bridge” which is responsible for redirecting read requests from the new component to the legacy data source, if the data have not already been migrated. The bridge is responsible for any necessary data conversion. The new component should not be aware of the bridge.
Figure 7.2: A Bridge helps you to transparently transfer data to the new system.
-
Adapt the legacy component to redirect write requests to the new component, so that the new data stay up-to-date.
-
When all the data have been transferred, remove the bridge and the legacy component.
Tradeoffs
Pros
- You can start using the new system without migrating all the legacy data.
Cons
-
A data bridge can be tricky to implement correctly if there is not a simple mapping between the legacy data and the new data.
-
Once some of the data has been transferred, it can be hard to go back.
-
The data bridge will add a performance overhead which may or may not be acceptable.
Difficulties
- “Stepwise migration schemes have proven very effective in large, layered business systems. They are not common in let’s say CAD applications that have check in /check out persistence and a tightly coupled and very woven object net.” [Kel00]
Known Uses
Brodie & Stonebraker discuss much more thoroughly the use of data bridges and gateways in Migrating Legacy Systems [BS95].
Keller in “The Bridge to the New Town” [Kel00] focusses more on the technical issue of migrating legacy data, and he points out numerous examples of the pattern successfully being applied.
There are many possible variants of this pattern, depending on whether the entire legacy system is to be replaced, or only a component, and whether users should be able to have access to both systems at the same time or not.
Rationale
A bridge between the old and new systems allows you to let users start using features of the new system before it is complete. The bridge isolates the two systems from each other so that the new system can be developed according to a new architectural vision without influence from the legacy system.
Related Patterns
A bridge helps you Migrate Systems Incrementally and thereby Build Confidence.
7.8 Present the Right Interface
Also Known As: Semantic Wrapper [O’C00], Sweeping it Under the Rug [FY00]
Intent Wrap a legacy system to export the right abstractions, even if they are not reflected in the existing implementation.
Problem
How should the new target system access legacy services during the migration process?
This problem is difficult because:
-
The target system is not yet complete so you must rely on legacy services during the migration.
-
The legacy system does not present the interfaces you need for the target system.
-
Implementing new components directly in terms of legacy components will bias the target towards the legacy architecture and design.
Yet, solving this problem is feasible because:
- You don’t have to access the legacy services directly.
Solution
Identify the abstractions that you want to have in the new system, and wrap up the old software to emulate the new abstractions.
Hints
Consider, for example, a procedural graphics library that will be used within an object-oriented system. It will be too costly and time-consuming to reimplement the library in an object-oriented way. It would be easier to wrap it as a utility class (i.e., as a class with static methods but no instances), but it would be wiser to write a slightly thicker wrapper that presents a truly object-oriented interface, but is implemented using the underlying procedural abstractions. In this way the new system will not be polluted by legacy abstractions.
Tradeoffs
Pros
-
It is easier to wean the target system from legacy services if they can use appropriate abstractions from the start.
-
You reduce the risk that the legacy design will adversely influence the new target.
Cons
- The new interface may not be stable, so developers may be reluctant to use it.
Difficulties
- It can be hard to resist the temptation to simply wrap the procedural abstractions as utility classes.
Known Uses
Alan O’Callaghan [O’C00] presents this pattern as “Semantic Wrapper” briefly in the context of the ADAPTOR pattern language, which addresses migration of large-scale business-critical legacy systems to object-oriented and component-based technology.
Rationale
Present the Right Interface frees you from thinking in terms of the legacy design and makes it easier to consider alternative approaches.
Related Patterns
Present the Right Interface superficially resembles an Adapter [p. 293], since both use wrappers as their implementation technique. An Adapter, however, adapts an incompatible interfaces to another interface expected by its clients. Present the Right Interface, on the other hand, introduces a new, more suitable interface to a legacy component.
Be sure to Deprecate Obsolete Interfaces.
If the new interface implemented by the Present the Right Interface is not stable, you should Distinguish Public from Published Interface.
7.9 Distinguish Public from Published Interface
Also Known As: Published Interface [O’C00]
Intent Facilitate parallel development by distinguishing unstable “published interfaces” from stable “public interfaces”.
Problem
How do you enable migration from legacy interfaces to new target interfaces while the new interfaces are still under development?
This problem is difficult because:
-
You want to enable migration to the new target system as early as possible.
-
You do not want to freeze the interfaces of new target components too early.
-
Changing the interface to a component that is widely used will slow down development.
Yet, solving this problem is feasible because:
- You can control the status of the interfaces you provide.
Solution
Distinguish between public interfaces of components that are available to the rest of the system, and unstable “published” interfaces of components that are available within a subsystem, but are not yet ready for prime time.
Hints
Since “published” interfaces are not supported by any programming language, you may have to use naming conventions, or abuse other features to achieve the desired effect.
-
In Java, consider declaring such interfaces as protected, or giving them package scope (undeclared). When the interfaces stabilize, you may redeclare them as being public.
-
In C++, consider declaring components with published interfaces private or protected, and declare as friends the clients that are permitted to use them. When the interfaces stabilize, redeclare the components as public, and delete the declarations of friends.
-
In Smalltalk, consider declaring categories of published components. Also consider declaring published message categories to distinguish stable and unstable messages.
-
Consider decorating the names of unstable components or interfaces to indicate their “published” status. When the component becomes public, rename it and patch all its clients or deprecate the version with the old name (Deprecate Obsolete Interfaces).
Tradeoffs
Pros
- Clients of published interfaces are aware that they are likely to change.
Cons
-
Identifying an interface as “published” is purely a matter of convention and discipline.
-
Promoting an interface from published to public entails a certain overhead for clients who should upgrade to the new interface.
Difficulties
- Clients can be put in a bind: should they use an unstable published interface, or continue to use the legacy service?
Known Uses
Published Interface is another pattern of the ADAPTOR pattern language [O’C00].
Rationale
Clients are in a better position to evaluate the risk of using a component if they know its interface is declared to be “published” but not yet public.
Related Patterns
When you Present the Right Interface to a legacy component, the new interface may not be stable, so be careful to Distinguish Public from Published Interface. When the new interface stabilizes, or is substituted by a stable replacement component, the interface may become public.
Upgrading an interface to public may entail a change to the way it is accessed. Be sure to Deprecate Obsolete Interfaces.
7.10 Deprecate Obsolete Interfaces
Also Known As: Deprecation [SP98]
Intent Give clients time to react to changes to public interfaces by flagging obsolete interfaces as “deprecated”.
Problem
How do you modify an interface without invalidating all the clients?
This problem is difficult because:
-
Changing a public interface can break many clients.
-
Leaving an obsolete interface in place will make future maintenance more difficult.
-
Not all changes are for the better.
Yet, solving this problem is feasible because:
- The old and the new interfaces can coexist for a period of time.
Solution
Flag the old interface as being “deprecated”, thereby notifying clients that it will almost certainly be removed in the next upcoming release.
Steps
-
You have determined that a public interface should be changed, but you do not want to break all clients. Implement the new interface, but “deprecate” the old one. The deprecation mechanism should inform clients that the interface has changed, and that a newer interface is recommended instead.
-
Evaluate to what extent the deprecated interface continues to be used, and whether it can be permanently retired. Consider removing it in a future release.
-
Java supports deprecation as a language feature:
- Deprecate a feature by adding the tag @deprecated to its Javadoc documentation. The tag is not only recognized by the Javadoc documentation generator, but the compiler will also generate compile-time warnings if code using deprecated features is compiled with the -deprecated option.
-
Other approaches are:
-
Simply inform users in the documentation which interfaces are deprecated.
-
Move or rename the deprecated interface or component. Clients can continue to use them, but must adapt and recompile to continue to use the deprecated form.
-
Replace deprecated components by equivalent ones that generate run-time warnings or output warnings to a log file.
-
Alternatively, consider configuring the programming environment or the deprecated components themselves to generate compile-time or link-time warnings.
-
Tradeoffs
Pros
-
Clients do not have to immediately adapt to changes.
-
There is time to change your mind.
Cons
- Clients are free to ignore deprecation.
Difficulties
-
It may be hard to track down all the clients of a deprecated component.
-
It can be hard to decide when to really retire a deprecated component.
-
If you want to keep the interface but change the semantics, you may need to introduce a new component and deprecate the old one. This can be the case if certain methods should now return default values instead of throwing exceptions (or vice versa).
Known Uses
Perdita Stevens and Rob Pooley identify Deprecation as a common practice for managing evolving APIs in complex systems [SP98].
Rationale
Deprecation gives you a window of time to evaluate the impact of a change.
7.11 Conserve Familiarity
Intent Avoid radical changes that may alienate users.
Problem
How do you accomplish a major overhaul of a legacy system without disrupting the way users are used to getting their job done?
This problem is difficult because:
-
The legacy system requires significant changes.
-
The users are not happy with the legacy system, but they understand it well.
Yet, solving this problem is feasible because:
- You can migrate incrementally to a new solution.
Solution
Introduce only a constant, relatively low number of changes between each new release.
Tradeoffs
Pros
- Users do not have to change their work habits too much between releases.
Difficulties
- Sometimes radical change is necessary. It can be hard to migrate from a command-line interface to a GUI while conserving familiarity.
Rationale
Too much change between releases increases the risk of hidden defects, and decreases the chance of user acceptance.
Lehman and Belady’s “Law of Conservation of Familiarity” suggests that the incremental change between releases of a system stays roughly constant over time [LB85]. This is a relatively natural phenomenon because to do anything else introduces unnecessary risks.
Related Patterns
To Conserve Familiarity you must Migrate Systems Incrementally. Involve the Users to understand what changes will be acceptable. Prototype the Target Solution to evaluate the potential impact of changes.
7.12 Use Profiler Before Optimizing
Intent Avoid squandering re-engineering effort on needless “optimizations” by verifying where the bottlenecks are.
Problem
When should you rewrite a clearly inefficient piece of code?
This problem is difficult because:
-
When you are re-engineering software, you are likely to encounter many naive algorithms in the legacy code.
-
It can be hard to predict what will impact performance, and you can lose a lot of time on pure supposition.
-
Optimized code is often more complex than simple, naive code.
Yet, solving this problem is feasible because:
- There are tools to tell you where you may have a performance problem.
Solution
Whenever you are tempted to optimize a “clearly inefficient” part of the system, first use a profiler to determine whether it is actually a bottleneck.
Don’t optimize anything unless your profiler tells you it will make a difference.
If you decide to go ahead, prepare benchmarks that will demonstrate the performance gains.
Tradeoffs
Pros
- You do not waste time optimizing something that will not make a difference to overall performance.
Cons
- Naive algorithms will survive longer in the system.
Rationale
The performance improvement that you can gain by optimizing a bit of code depends on how much time the program, spends in that code in a typical run. A profiler will tell you how much time that is.
“Do it, then do it right, then do it fast” is a well-known aphorism that has been credited to many different sources. Very likely its origin is outside of the field of computer science. The rationale behind it is that you risk making a system complex and hard to maintain if you become preoccupied with performance issues too early. Instead, it is better to first find a solution that works, then clean it up once you understand it. Finally, if you can identify any important performance bottlenecks, that is the time to optimize just those parts that will make a difference.
As a corollary, it may even be a good idea to replace a bit of complex, “optimized” code by a simpler, “naive” solution, if that won’t severely impact performance, but will make it easier to make other changes.
See also Davis’ discussion of “Use Profiler Before Optimizing” [Dav95].
Related Patterns
If you Refactor to Understand [p. 115], you will have started the second step to “do it right.”