Introduction to the shell for absolute beginners
In this tutorial, you’ll understand:
- Understand what the shell is, how to access it from your computer, and how to use it.
- Navigate around a Unix file system to view and manipulate files
In this chapter
- What is the shell?
- How to access the shell
- Preliminaries
- Moving around the file system
- Arguments
- Examining the contents of other directories
- Full vs. Relative Paths
- Saving time with shortcuts, wild cards, and tab completion
- Command History
- Examining Files
- Searching files
- Redirection
- Creating, moving, copying, and removing
- Writing files
- Running programs
- Writing scripts
What is the shell?
The shell is a program that presents a command line interface which allows you to control your computer using commands entered with a keyboard instead of controlling graphical user interfaces (GUIs) with a mouse/keyboard combination.
There are many reasons to learn about the shell.
- The shell gives you power. The command line gives you the power to do your work more efficiently and more quickly. When you need to do things tens to hundreds of times, knowing how to use the shell is transformative.
- To use remote computers or cloud computing, you need to use the shell.
- We’re going to use it in this class, for all of the reasons above.
Unix is user-friendly. It’s just very selective about who its friends are.
Today we’re going to go through how to access Unix/Linux and some of the basic shell commands.
How to access the shell
The shell is already available on Mac and Linux. For Windows, you’ll have to download a separate program.
Mac
On Mac the shell is available through Terminal Applications -> Utilities -> Terminal Go ahead and drag the Terminal application to your Dock for easy access.
Windows
For Windows, we’re going to be using MobaXTerm. Download and install MobaXterm Open up the program.
Linux
Well, you should be set if you’re already using Linux
Preliminaries
Create a folder named tutorial_shell.
Moving around the file system
Let’s practice moving around a bit.
We’re going to work in that tutorial_shell you just created.
Let’s navigate there using the regular way by clicking on the different folders.
First we did something like go to the folder of our username. Then we clicked on an n number of directories then eventually ‘tutorial_shell’
Let’s draw out how that went.
Now let’s draw some of the other files and folders we could have clicked on.
This is called a hierarchical file system structure, like an upside down tree with root (/) at the base that looks like this.
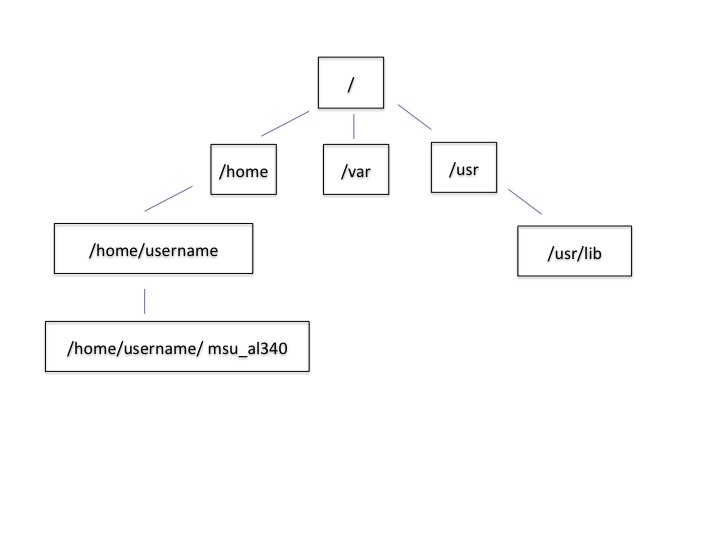
That (/) at the base is often also called the ‘top’ level.
When you are working at your computer or log in to a remote computer, you are on one of the branches of that tree, your home directory (/home/username)
Now let’s go do that same navigation at the command line.
Open The Shell
Congrats! You are in the home directory. Just to be sure, let’s type:
cd
This command will always place you home.
This directory should have some other folders, perhaps files and/or programs. Let’s check. Type:
ls
ls stands for ‘list’ and it lists the contents of a directory.
Oftentimes, a directory will have a mix of objects. If we want to know which is which, we can type:
ls -F
Anything with a “/” after it is a directory. Things with a “*” after them are programs. It there’s nothing there it’s a file.
You can also use the command ls -l to see whether items in a directory are files or directories. ls -l gives a lot more information too, such as the size of the file
As you are seeing the list of directories in the home folder, pick one and type:
cd <name of directory>
You have just entered a lower level directory of your choice. Check out its contents by typing:
ls
To go ‘back up a level’ we need to use ..
Type:
cd ..
Sometimes when we’re wandering around in the file system, it’s easy to lose track of where we are and get lost.
If you want to know what directory you’re currently in, type:
pwd
This stands for ‘print working directory’. The directory you’re currently working in.
We are ready. Using cd <directory>, ls and (optionally) pwd, to the tutorial_shell directory and list its contents. Remember, if you get lost, going home is easy with cd by itself.
Good work. You can now move around in different directories or folders at the command line. Why would you want to do this, rather than just navigating around the normal way?
Arguments
Most programs take additional arguments that control their exact behavior. For example, -F and -l are arguments to ls. The ls program, like many programs, take a lot of arguments. But how do we know what the options are to particular commands?
Most commonly used shell programs have a manual. You can access the manual using the man program. Try entering:
man ls
This will open the manual page for ls. Use the space key to go forward and b to go backwards. When you are done reading, just hit q to quit.
Programs that are run from the shell can get extremely complicated. To see an example, open up the manual page for the find program. No one can possibly learn all of these arguments, of course. So you will probably find yourself referring back to the manual page frequently.
Examining the contents of other directories
By default, the ls command lists the contents of the working directory (i.e. the directory you are in). You can always find the directory you are in using the pwd command. However, you can also give ls the names of other directories to view. Navigate to the tutorial_shell directory if you are not already there.
Type:
cd ..
Then enter the command:
ls tutorial_shell
This will list the contents of the tutorial_shell directory without
you having to navigate there.
The cd command works in a similar way. Using cd .. twice, navigate two levels higher than tutorial_shell. Now navigate back to tutorial shell in one line of code that looks something like:
cd <directory_1>/<directory_2>/tutorial_shell
and you will jump directly to tutorial_shell without having to go through
the intermediates.
Full vs. Relative Paths
The cd command takes an argument which is the directory name. Directories can be specified using either a relative path or a full path. The directories on the computer are arranged into a hierarchy. The full path tells you where a directory is in that hierarchy. Navigate to the home directory. Now, enter the pwd command and you should see:
/home/<username>
which is the full name of your home directory. This tells you that you are in a directory called <username>, which sits inside a directory called home which sits inside the very top directory in the hierarchy. The very top of the hierarchy is a directory called / which is usually referred to as the root directory. So, to summarize: <username> is a directory in home which is a directory in /.
Let’s try an exercise. Navigate to the tutorial_shell directory if you are not already there.
Check where you are with pwd. The output should look something like /home/<username>/.../tutorial_shell Copy the entire output. Next, go to the home directory with cd. Once in home directory, type:
cd <pwd output>
This jumps back to the tutorial_shell.
Now go back to the home directory again with cd. Once in home directory, type cd plus the output of pwd minus the /home/<username>
The reduced command had the same effect - it took us to the tutorial_shell directory. But, instead of specifying the full path, which starts with the root directory /, we specified a relative path. In other words, we specified the path relative to our current directory. A full path always starts with a /. A relative path does not.
A relative path is like getting directions from someone on the street. They tell you to “go right at the Stop sign, and then turn left on Main Street”. That works great if you’re standing there together, but not so well if you’re trying to tell someone how to get there from another country. A full path is like GPS coordinates. It tells you exactly where something is no matter where you are right now.
You can usually use either a full path or a relative path depending on what is most convenient. If we are in the home directory, it is more convenient to just enter the relative path since it involves less typing.
Over time, it will become easier for you to keep a mental note of the structure of the directories that you are using and how to quickly navigate amongst them.
Saving time with shortcuts, wild cards, and tab completion
Shortcuts
There are some shortcuts which you should know about. Dealing with the home directory is very common. So, in the shell the tilde character, ~, is a shortcut for your home directory. Navigate to the tutorial_shell directory:
Then enter the command:
ls ~
This prints the contents of your home directory, without you having to type the full path. The shortcut .. always refers to the directory above your current directory. Thus:
ls ..
prints the contents of the directory one level higher than tutorial_shell. You can chain these together, so:
ls ../../
prints the contents of two levels higher than tutorial_shell. Finally, the special directory . always refers to your current directory. So, ls, ls ., and ls ././././. all do the same thing, they print the contents of the current directory. This may seem like a useless shortcut right now, but we’ll see when it is needed in a little while.
To summarize, while you are in the shell directory, the commands ls ~, ls ~/., ls ../../, and ls /home/username all do exactly the same thing. These shortcuts are not necessary, they are provided for your convenience.
Wild cards
The * character is a shortcut for “everything”. Thus, if you enter ls *, you will see all of the contents of a given directory. Now try this command:
ls *fastq
This lists every file that ends with a fastq. This command:
ls /usr/bin/*.sh
Lists every file in /usr/bin that ends in the characters .sh.
We have paired end sequencing, so for every sample we have two files. If we want to just see the list of the files for the forward direction sequencing we can use:
ls *F*fastq
lists every file in the current directory whose name contains the letter F, and ends with fastq.
So how does this actually work? Well…when the shell (bash) sees a word that contains the \* character, it automatically looks for filenames that match the given pattern. In this case, it identified four such files. Then, it replaced the *F*fastq with the list of files, separated by spaces. In other words, the two commands:
ls *F*fastq
ls C01D01F_sub.fastq C01D02F_sub.fastq C01D03F_sub.fastq
are exactly identical. The ls command cannot tell the difference between these two things.
Tab Completion
Navigate to the home directory. Typing out directory names can waste a lot of time. When you start typing out the name of a directory, then hit the tab key, the shell will try to fill in the rest of the directory name. For example, enter:
cd <someletter><tab>
The shell will fill in the rest of the directory name.
ls C<tab><tab>
When there there are multiple directories in the home directory which start with C, the shell does not know which one to fill in. When you hit tab again, the shell will list the possible choices.
Tab completion can also fill in the names of programs. For example, enter e<tab><tab>. You will see the name of every program that starts with an e. One of those is echo. If you enter ec<tab> you will see that tab completion works.
Command History
You can easily access previous commands. Hit the up arrow. Hit it again. You can step backwards through your command history. The down arrow takes your forwards in the command history.
^-C will cancel the command you are writing, and give you a fresh prompt.
^-R will do a reverse-search through your command history. This is very useful.
You can also review your recent commands with the history command. Just enter:
history
to see a numbered list of recent commands, including this just issues history command. You can reuse one of these commands directly by referring to the number of that command.
If your history looked like this:
259 ls *
260 ls /usr/bin/*.sh
261 ls *F*fastq
then you could repeat command #260 by simply entering:
!260
(that’s an exclamation mark by the way).
Examining Files
We now know how to switch directories, run programs, and look at the contents of directories, but how do we look at the contents of files?
The easiest way to examine a file is to just print out all of the contents using the program cat. Enter the following command:
cat C01D01R_sub.fastq
This prints out the contents of the C01D01R_sub.fastq file.
cat is a terrific program, but when the file is really big, it can be annoying to use. The program, less, is useful for this case. Enter the following command:
less C01D01R_sub.fastq
less opens the file, and lets you navigate through it. The commands are identical to the man program. To quit less and go back to the shell, press q.
Some commands in less
| key | action |
|---|---|
| “space” | to go forward |
| “b” | to go backwarsd |
| “g” | to go to the beginning |
| “G” | to go to the end |
| “q” | to quit |
less also gives you a way of searching through files. Just hit the “/” key to begin a search. Enter the name of the word you would like to search for and hit enter. It will jump to the next location where that word is found. If you hit “/” then “enter”, less will just repeat the previous search. less searches from the current location and works its way forward. If you are at the end of the file and search for the word that does not exist from that point forward, less will not find it. You need to go to the beginning of the file and search.
For instance, let’s search for the sequence HWI-M03127:41:ACE13:1:1114:22908:11882 in our file. You can see that we go right to that sequence and can see what it looks like.
Remember, the man program actually uses less internally and therefore uses the same commands, so you can search documentation using “/” as well!
There’s another way that we can look at files, and in this case, just look at part of them. This can be particularly useful if we just want to see the beginning or end of the file, or see how it’s formatted.
The commands are head and tail and they just let you look at the beginning and end of a file respectively.
head C01D01R_sub.fastq
tail C01D01R_sub.fastq
The -n option to either of these commands can be used to print the first or last n lines of a file. To print the first/last line of the file use:
head -n 1 C01D01R_sub.fastq
tail -n 1 C01D01R_sub.fastq
Searching files
We showed a little how to search within a file using less. We can also search within files without even opening them, using grep. Grep is a command-line utility for searching plain-text data sets for lines matching a string or regular expression. Let’s give it a try!
Let’s search for that sequence ACE13:1:2109:11596: in the C01D01R_sub.fastq file.
grep ACE13:1:2109:11596 C01D01R_sub.fastq
We get back the whole line that had ‘1101:14341’ in it. What if we wanted all four lines, the whole part of that FASTQ sequence, back instead.
grep -A 3 ACE13:1:2109:11596 C01D01R_sub.fastq
The -A flag stands for “after match” so it’s returning the line that matches plus the three after it. The -B flag returns that number of lines before the match.
Redirection
We’re excited we have all these sequences that we care about that we just got from the FASTQ files. That is a really important motif that is going to help us answer our important question. But all those sequences just went whizzing by with grep. How can we capture them?
We can do that with something called “redirection”. The idea is that we’re redirecting the output to the terminal (all the stuff that went whizzing by) to something else. In this case, we want to print it to a file, so that we can look at it later.
The redirection command for putting something in a file is >
Let’s try it out and put all the sequences that contain ‘CCTGTTTGCTCCCCACGCTCTCGCACCTCAGTGTCA’ from all the files in to another file called ‘good-data.txt’
grep -B 2 CCTGTTTGCTCCCCACGCTCTCGCACCTCAGTGTCA * > good-data.txt
The above code makes use of the * wilcard to search ALL of the files in your current directory for the sequence. The > here says to write the results from the grep command we just ran to a new file called good-data.txt The prompt should sit there a little bit, and then it should look like nothing happened. But type ls. You should have a new file called good-data.txt. Take a look at it and see if it has what you think it should.
There’s one more useful redirection command that we’re going to show, and that’s called the pipe command, and it is |. It’s probably not a key on your keyboard you use very much. What | does is take the output that scrolling by on the terminal and then can run it through another command. When it was all whizzing by before, we wished we could just slow it down and look at it, like we can with less. Well it turns out that we can! We pipe the grep command through less.
grep CCTGTTTGCTCCCCACGCTCTCGCACCTCAGTGTCA * | less
Now we can use the arrows to scroll up and down and use q to get out.
We can also do something tricky and use the command wc. wc stands for word count. It counts the number of lines or characters. So, we can use it to count the number of lines we’re getting back from our grep command. And that will magically tell us how many sequences we’re finding. We’re
grep CCTGTTTGCTCCCCACGCTCTCGCACCTCAGTGTCA * | wc
That tells us the number of lines, words and characters in the file. If we just want the number of lines, we can use the -l flag for lines.
grep CCTGTTTGCTCCCCACGCTCTCGCACCTCAGTGTCA * | wc -l
Redirecting is not super intuitive, but it’s really powerful for stringing together these different commands, so you can do whatever you need to do.
The philosophy behind these command line programs is that none of them really do anything all that impressive. BUT when you start chaining them together, you can do some really powerful things really efficiently. If you want to be proficient at using the shell, you must learn to become proficient with the pipe and redirection operators: |, >, >>.
Creating, moving, copying, and removing
Now we can move around in the file structure, look at files, search files, redirect. But what if we want to do normal things like copy files or move them around or get rid of them. Sure we could do most of these things without the command line, but what fun would that be?! Besides it’s often faster to do it at the command line, or you’ll be on a remote server like Amazon where you won’t have another option.
The Centralia_Full_Map.txt is one that tells us what environmental data goes with which samples. This is a really important file, so we want to make a copy so we don’t lose it.
Lets copy the file using the cp command. The cp command backs up the file. Navigate to the Fastq/MappingFiles directory and enter:
cp Centralia_Full_Map.txt Centralia_Full_Map_backup.txt
Now Centralia_Full_Map_backup.txt has been created as a copy of Centralia_Full_Map.txt.
Let’s make a backup directory where we can put this file.
The mkdir command is used to make a directory. Just enter mkdir followed by a space, then the directory name.
mkdir backup
We can now move our backed up file in to this directory. We can move files around using the command mv. Enter this command:
mv Centralia_Full_Map_backup.txt backup/
This moves Centralia_Full_Map_backup.txt into the directory backup/. Check the full path of backup with pwd
The mv command is also how you rename files. Since this file is so important, let’s rename it:
mv Centralia_Full_Map.txt Centralia_Full_Map_IMPORTANT.txt
Now the file name has been changed to Centralia_Full_Map_IMPORTANT.txt. Let’s delete the backup file now:
rm backup/Centralia_Full_Map_backup.txt
The rm file removes the file. Be careful with this command. It doesn’t just nicely put the files in the Trash. They’re really gone.
By default, rm, will NOT delete directories. You can tell rm to
delete a directory using the -r option. Let’s delete that new directory
we just made. Enter the following command:
rm -r new
Writing files
We’ve been able to do a lot of work with files that already exist, but what if we want to write our own files. Obviously, we’re not going to type in a FASTA file, but you’ll see as we go through other tutorials, there are a lot of reasons we’ll want to write a file, or edit an existing file.
To write in files, we’re going to use the program nano. We’re going to create a file that contains the favorite grep command so you can remember it for later. We’ll name this file ‘awesome.sh’.
nano awesome.sh
Type in your command, so it looks like
grep -B 1 CCTGTTTGCTCCCCACGCTCTCGCACCTCAGTGTCA * > good_data.txt
Now we want to save the file and exit. At the bottom of nano, you see the “^X Exit”. That means that we use Ctrl-X to exit. Type Ctrl-X. It will ask if you want to save it. Type y for yes. Then it asks if you want that file name. Hit ‘Enter’.
Now you’ve written a file. You can take a look at it with less or cat, or open it up again and edit it.
Running programs
Commands like ls, rm, echo, and cd are just ordinary programs on the computer. A program is just a file that you can execute. The program which tells you the location of a particular program. For example:
which ls
Will return “/bin/ls”. Thus, we can see that ls is a program that sits inside of the /bin directory. Now enter:
which find
You will see that find is a program that sits inside of the /usr/bin directory.
So … when we enter a program name, like ls, and hit enter, how does the shell know where to look for that program? How does it know to run /bin/ls when we enter ls. The answer is that when we enter a program name and hit enter, there are a few standard places that the shell automatically looks. If it can’t find the program in any of those places, it will print an error saying “command not found”. Enter the command:
echo $PATH
This will print out the value of the PATH environment variable. More on environment variables later. Notice that a list of directories, separated by colon characters, is listed. These are the places the shell looks for programs to run. If your program is not in this list, then an error is printed. The shell ONLY checks in the places listed in the PATH environment variable.
Navigate to the shell directory and list the contents. You will notice that there is a program (executable file) called hello.sh in this directory. Now, try to run the program by entering:
hello.sh
You should get an error saying that hello.sh cannot be found. That is because the directory tutorial_shell is not in the PATH. You can run the hello.sh program by entering:
./hello.sh
Remember that . is a shortcut for the current working directory. This tells the shell to run the hello.sh program which is located right here. So, you can run any program by entering the path to that program. You can run hello.sh equally well by specifying its full path.
Writing scripts
We know how to write files and run scripts, so I bet you can guess where this is headed. We’re going to run our own script!
Go in to the ‘MiSeq’ directory where we created ‘awesome.sh’ before. Remember we wrote our favorite grep command in there. Since we like it so much, we might want to run it again, or even all the time. Instead of writing it out every time, we can just run it as a script.
It’s a command, so we should just be able to run it. Give it try.
./awesome.sh
Alas, we get -bash: ./awesome.sh: Permission denied. This is because we haven’t told the computer that it’s a program. To do that we have to make it ‘executable’. We do this by changing its mode. The command for that is chmod - change mode. We’re going to change the mode of this file, so that it’s executable and the computer knows it’s OK to run it as a program.
chmod +x awesome.sh
Now let’s try running it again:
./awesome.sh
Now you should have seen some output, and of course, it’s AWESOME! Congratulations, you just created your first shell script! You’re set to rule the world.
For Future Reference
Finding files
The find program can be used to find files based on arbitrary criteria. Navigate to the data directory and enter the following command:
find . -print
This prints the name of every file or directory, recursively, starting from the current directory. Let’s exclude all of the directories:
find . -type f -print
This tells find to locate only files. Now try these commands:
find . -type f -name "*1*"
find . -type f -name "*1*" -or -name "*2*" -print
find . -type f -name "*1*" -and -name "*2*" -print
The find command can acquire a list of files and perform some operation on each file. Try this command out:
find . -type f -exec grep Volume {} \;
This command finds every file starting from .. Then it searches each file for a line which contains the word “Volume”. The {} refers to the name of each file. The trailing \; is used to terminate the command. This command is slow, because it is calling a new instance of grep for each item the find returns.
A faster way to do this is to use the xargs command:
find . -type f -print | xargs grep Volume
find generates a list of all the files we are interested in, then we pipe them to xargs. xargs takes the items given to it and passes them as arguments to grep. xargs generally only creates a single instance of grep (or whatever program it is running).
LICENSE: Original content Introduction to the shell - EDAMAME tutorials. Edited to remove broken links and updated some text. Used under CC-BY. This content is available under CC-BY-SA.