Machine Learning in Production
This article is intended to stimulate discussions about how to use machine learning in production (system components, processes, challenges/pitfalls etc.
Overview
The following figure summarizes the components/processes involved:
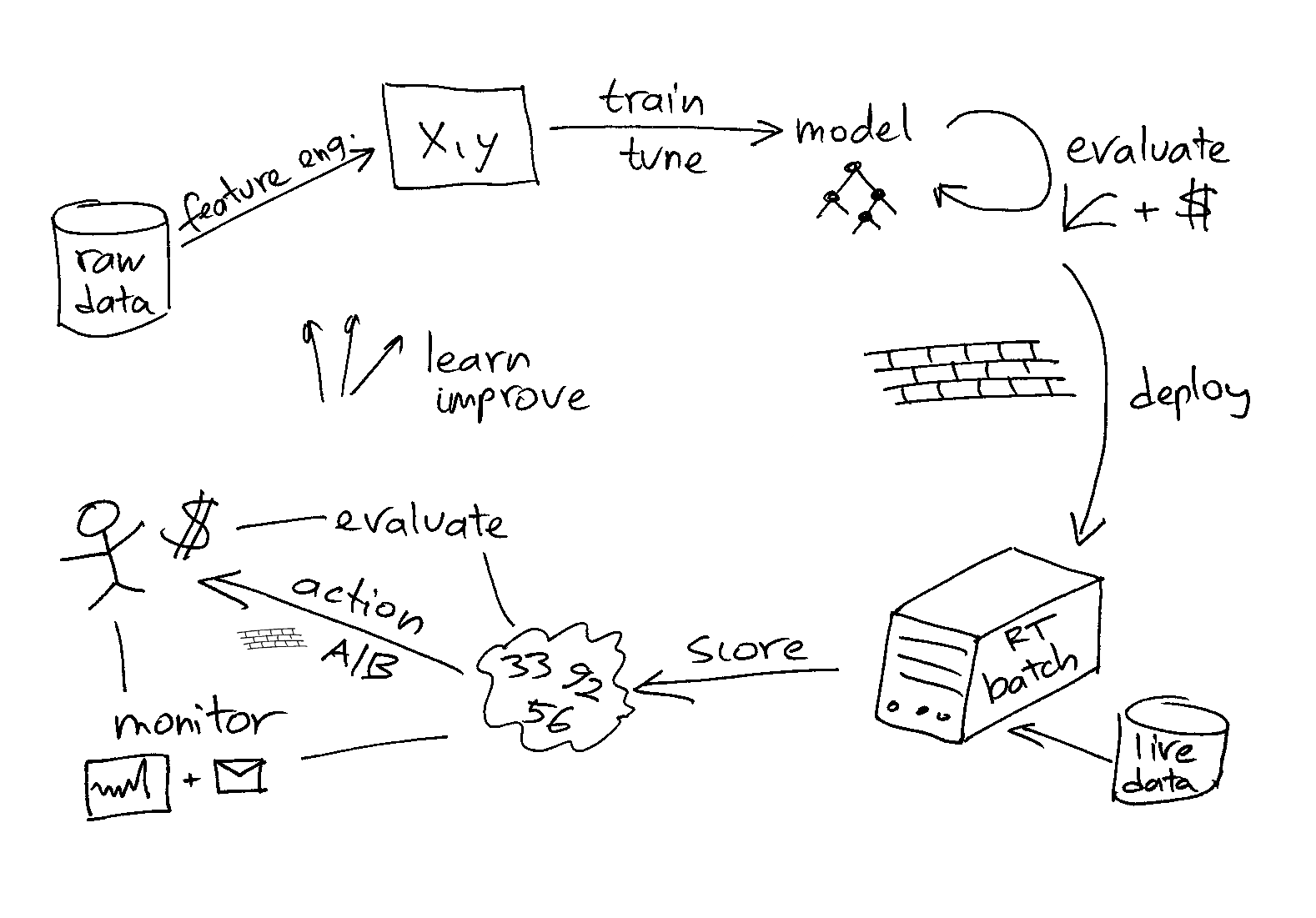
Historical data
Can be in database, csv file(s), data warehouse, HDFS
Feature engineering
On typical structured/tabular business data it can involve joins and aggregates (e.g. how many clicks from a given user in given time period)
This “ETL” is heavy processing, not suited for operational systems (e.g. MySQL), usually in “analytical” database (Vertica, Redshift) or maybe Spark
Figuring out good features is trial-error/iterative/researchy/exploratory/time consuming (as in general the whole upper part of the Figure above, i.e. FE, model training and evaluation)
Categorial variables: some modeling tools require transformation to numeric (e.g. one-hot encoding)
Training, tuning
The result of feature engineering is a “data matrix” with features and labels (in case of supervised learning)
This data is usually smaller and most often does not require distributed systems
The algos with best performance are usually: gradient boosting (GBM), random forests, neural networks (and deep learning), support vector machines (SVM)
In certain cases (sparse data, model interpretability required) linear models must be used (e.g. logistic regression)
There are good open source tools for all this (R packages, Python sklearn, xgboost, VW, H2O etc.)
The name of the game is avoid overfitting (and techniques such as regularization are used)
Also need unbiased evaluation, see next point
Models can be tuned by search in the hyperparameter space (grid or random search, Bayesian optimization methods etc.)
Performance can be often increased further by ensembling several models (averaging, stacking etc.), but drawbacks/tradeoffs (increased complexity in deploying such models)
Model evaluation
This is super-important, spend a lot of time here
Unbiased evaluation with test set, cross validation (some algos have “early stoping” requiring a validation set)
If you did hyperparameter tuning, that also needed a separate validation set (or cross validation)
The real world is non-stationary, use a time gapped test set
Diagnostics: distribution of probability scores, ROC curves etc.
Also do evaluation using relevant business metrics (impact of model in business terms)
Model deployment
Scoring of live data
Considered usually an “engineering” task (thrown over a “wall” from data scientists to software engineers)
Use same tool to deploy, do not rewrite in other “language” or tool (SQL, PMML, Java, C++, custom format such as JSON) (unless the export is done by the same tool/vendor doing the training) (high risk of subtle bugs in edge cases)
Different servers (training requires more CPU/RAM; scoring requires low latency, high-availability, maybe scalability)
Live data comes from a different system, often FE needs to be replicated (duplicate code is evil, but may be unavoidable); transformations/data cleaning already in the historical data might need to be duplicated here as well
Scoring can be batch (easier, can read from database, score and write results back to database) or real-time (the modern way to do it is via http REST API provinding a separation of concerns)
Better IMO if data science team owns this part as well (along with as much as possible of the lower part of the Figure above, possibly with some engineering support)
Taking action
The primary goal of an ML system in a company is to provide some business value (happy customers, $$$ etc.)
Action probably must be owned by the engineering team (therefore “wall” moved around here?)
Ability to test live/roll out gradually (A/B testing of models)
Evaluate & monitor
Models might behave differently in production vs train-test (non-stationarity, changed conditions, wrong assumptions, bugs etc.)
Crucial to evaluate the models after deployment
Evaluation based on ML metrics (distribution of scores etc.) and business metrics (impact of taking action)
Evaluation after deployment and continuous monitoring subsequently (dashboards and alerts) (to detect if something external changes/breaks it, also models can slowly degrade in time)
This too should be owned by the data science team (expertise to compare with the model developed offline)
Misc
ML creates tight couplings that is considered evil from engineering perspective
Some problems identified in this paper although no silver bullet solutions exist at the moment (keep in mind/mitigate as much as possible though)
Some ideas for a framework are here (also described here)
Example couplings: FE to data schemas (can change upstream), duplicated FE in scoring, action taking couples with lots of engineering/business domain
ML needs to be “sold” to the business side (management/business units in the application domain of each ML product)
Involving the business into ML’s inner working and showing business inpact on a on-going basis (reports, dashboards, alerts etc.) can help trust/buy-in
Learn & improve
Iterate over all the components, learn from the experience of using it in practice (e.g. incorporate ideas from business, add new features to FE, retrain models if performance degrade in time etc.)
For iterations to be fast, as much of the above should use tools that facilitate automation/reproducibity (e.g. Rstudio+R-markdown/Jupyter notebooks, git, docker etc.)
Licenses and Attribution
Copyright (C) CodeAhoy. Licensed under Creative Commons Attribution- ShareAlike 4.0 International License
Original Content: Machine Learning in Production used under CC-BY 4.0.