Related Books





Books / Recursion in Java / Chapter 1
Recursive Problem Solving in Java
The pattern in the figure below is known as the Sierpinski gasket. Its overall shape is that of an equilateral triangle. But notice how inside the outer triangle there are three smaller triangles that are similar to the overall pattern. And inside each of those are three even smaller triangles, and so on. The Sierpinski gasket is known as a fractal because when you divide it up, you end up with a smaller version of the overall pattern. The overall gasket pattern is repeated over and over, at smaller and smaller scales, throughout the figure.

Sierpiński triangle in Java. Image Credit: Beojan Stanislaus [Wikipedia]used under CC BY-SA 3.0
{kind=link}
How would you draw this pattern? If you try to use some kind of nested loop structure, you’ll find that it is very challenging. It can be done using loops, but it isn’t easy. On the other hand, if you use an approach known as recursion, this problem is much easier to solve. Your ability to solve a problem often depends on how you represent the problem. Recursion gives you another way to approach problems that involve repetition, such as the problem of drawing the Sierpinski gasket.
The main goal of this tutorial is to introduce recursion as both a problem-solving technique and as alternative to loops for implementing repetition. We begin with the notion of a recursive definition, a concept used widely in mathematics and computer science. We then introduce the idea of a recursive method, which is the way recursion is implemented in a program.
Recursion is a topic that is taken up in considerable detail in upper-level computer science courses, so our goal here is mainly to introduce the concept and give you some idea of its power as a problem-solving approach. To illustrate recursion, we use a number of simple examples throughout the chapter. One risk in using simple examples, though, is that you might be tempted to think that recursion is only good for “toy problems.” Nothing could be further from the truth. Recursion is often used for some of the most difficult algorithms. Some of the exercises at the end of the chapter are examples of more challenging problems.
Recursion vs Iteration
A recursive method is a method that calls itself. An iterative method is a method that uses a loop to repeat an action. In one sense, recursion is an alternative to the iterative (looping) control structures. In this sense, recursion is just another way to repeat an action.
To understand the difference between Recursion and Iteration, consider the following iterative method for saying “Hello” N times:
public void hello(int N) {
for (int k = 0; k < N; k++)
System.out.println("Hello");
}
A recursive version of this method would be defined as follows:
public void hello(int N) {
if (N > 0) {
System.out.println("Hello");
hello(N - 1); // Recursive call
}
}
This method is recursive because it calls itself when N is greater than 0. However, note that when it calls itself, it passes N-1 as the value for its parameter. If this method is initially called with N equal to 5, the following is a trace of what happens. The indentations indicate each time the method calls itself:
hello(5)
Print "Hello"
hello(4)
Print "Hello"
hello(3)
Print "Hello"
hello(2)
Print "Hello"
hello(1)
Print "Hello"
hello(0)
Thus, “Hello” will be printed five times, just as it would be in the iterative version of this method.
So, in one sense, recursion is just an alternative to iteration. In fact, there are some programming languages, such as the original versions of LISP and PROLOG, that do not have loop structures. In these languages, all repetition is done by recursion. In contrast, if a language contains loop structures, it can do without recursion. Anything that can be done iteratively can be done recursively, and vice versa.
Moreover, it is much less efficient to call a method five times than to repeat a for loop five times. Method calls take up more memory than loops and involve more computational overhead—for such tasks as passing parameters, allocating storage for the method’s local variables, and returning the method’s results. Therefore, because of its reliance on repeated method calls, recursion is often less efficient than iteration as a way to code a particular algorithm.
What would be printed if we call the following method with the expression mystery(0)?
public void mystery(int N) {
System.out.print(N + " ");
if (N <= 5)
mystery(N + 1);
}
Output:
0 1 2 3 4 5 6
Why use Recursion? Recursion as a Problem-Solving Approach
Given that recursion is not really necessary—if a programming language has loops—and is not more efficient than loops, why is it so important? The answer is that, in a broader sense, recursion is an effective approach to problem solving. It is a way of viewing a problem. It is mostly in this sense that we want to study recursion.
Recursion is based on two key problem-solving concepts:
- divide and conquer
- self-similarity
In recursive problem solving we use the divide-and-conquer strategy repeatedly to break a big problem into a sequence of smaller and smaller problems until we arrive at a problem that is practically trivial to solve.
What allows us to create this series of sub-problems is that each subproblem is similar to the original problem—that is, each subproblem is just a smaller version of the original problem. Look again at the task of saying “Hello” N times. Solving this task involves solving the similar task of saying “Hello” N-1 times, which can be divided into the similar task of saying “Hello” N-2 times. And so on.
The ability to see a problem as being composed of smaller, self-similar problems is at the heart of the recursive approach. And although you might not have thought about this before, a surprising number of programming problems have this self-similarity characteristic. Let’s illustrate these ideas with some simple examples.
Definition of Recursion
One place you might have already seen recursion is in mathematics. A recursive definition consists of two parts:
- a recursive part in which the nth value is defined in terms of the (n-1)st value, and,
- a non-recursive, boundary or base case, which defines a limiting condition.
Recursion Example: N! Factorial
For example, consider the problem of calculating the factorial of n, that is, n! for n>0 . As you may recall, n! is calculated as follows:
n! = n * (n-1) * (n-2) * ... * 1, for n > 0
In addition, 0! is defined as 1. Let’s now look at some examples for different values of n:
4! = 4 * 3 * 2 * 1 = 24
3! = 3 * 2 * 1 = 6
2! = 2 * 1 = 2
1! = 1
0! = 1
As these examples suggest, n! can always be calculated in terms of (𝑛−1)! This relationship might be clearer if we rewrite the previous calculations as follows:
4! = 4 * 3 * 2 * 1 = 4 * 3! = 24
3! = 3 * 2 * 1 = 3 * 2! = 6
2! = 2 * 1 = 2 * 1! = 2
1! = 1 * 0! = 1
0! = 1
The only case in which we can’t calculate n! in terms of (𝑛−1) ! is when n is 0. Otherwise, in each case we see that
n! = n * (n-1)!
This leads to the following recursive definition:
n! = 1 if n = 0 // Boundary (or base) case
n! = n * (n-1)! if n > 0 // Recursive case
Note that if we had omitted the base case, the recursion would have continued to (−1) ! and (−2) ! and so on.
The recursive case uses divide and conquer to break the problem into a smaller problem, but the smaller problem is just a smaller version of the original problem. This combination of self-similarity and divide and conquer is what characterizes recursion. The base case is used to stop or limit the recursion.
Recursion Example: Drawing a Nested Pattern
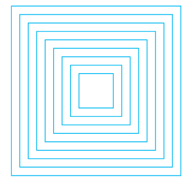
The nested squares pattern
As another example, consider the problem of drawing the nested boxes pattern shown in figure above. The self-similarity occurs in the fact that for this pattern, its parts resemble the whole. The basic shape involved is a square, which is repeated over and over at an ever-smaller scale. A recursive definition for this pattern would be
Base case: if side < 5 do nothing
Recursive case: if side >= 5
draw a square
decrease the side and draw a smaller
pattern inside the square
This definition uses the length of the square’s side to help define the pattern. If the length of the side is greater than or equal to 5, draw a square with dimensions 𝑠𝑖𝑑𝑒×𝑠𝑖𝑑𝑒 . Then decrease the length of the side and draw a smaller version of the pattern inside that square. In this case, the side variable will decrease at each level of the drawing. When the length of the side becomes less than 5, the recursion stops. Thus, the length of the side serves as the limit or bound for this algorithm.
You should note that the length of the side functions here like a parameter in a method definition: It provides essential information for the definition, just as a method parameter provides essential data to the method. Indeed, this is exactly the role that parameters play in recursive methods. They provide essential information that determines the method’s behavior.
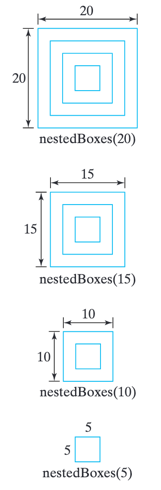
Figure below illustrates how we would apply the definition. Suppose the side starts out at 20 and decreases by 5 at each level of recursion. Note that as you move from top to bottom across the four patterns, each pattern contains the one below it. A nestedBoxes(20) can be drawn by first drawing a 20×20 square and then drawing a nestedBoxes(15) pattern inside it. Similarly, a nestedBoxes(15) can be drawn by first drawing a 15×15 square and then drawing a nestedBoxes(10) pattern inside it. And so on.
A trace of the nested boxes definition starting with a side of 20 and decreasing the side by 5 each time.
These examples illustrate the power of recursion as a problem-solving technique for situations that involve repetition. Like the iterative (looping) control structures, recursion is used to implement repetition within a bound. For recursive algorithms, the bound is defined by the base case, whereas for loops, the bound is defined by the loop’s entry condition. In either case, repetition stops when the bound is reached.
You can calculate 2𝑛 by multiplying 2 by itself n times. For example, 23 is 2×2×2 . Note also that 20=1 . Given these facts, write a recursive definition for 2𝑛 , for 𝑛≥0 .