Related Books





Books / Recursion in Java / Chapter 6
Recursion or Iteration - Differences and When to Use Which
A recursive method is a method that calls itself. An iterative method is a method that uses a loop to repeat an action. In one sense, recursion is an alternative to the iterative (looping) control structures. In this sense, recursion is just another way to repeat an action.
To understand the difference between Recursion and Iteration, consider the following iterative method for saying “Hello” N times:
public void hello(int N) {
for (int k = 0; k < N; k++)
System.out.println("Hello");
}
A recursive version of this method would be defined as follows:
public void hello(int N) {
if (N > 0) {
System.out.println("Hello");
hello(N - 1); // Recursive call
}
}
As we mentioned earlier, recursive algorithms require more computational overhead than iterative algorithms. We’re now in a good position to appreciate why this is so.
A recursive algorithm incurs two kinds of overhead that are not incurred by an iterative algorithm: memory and CPU time. Both of these are direct results of the fact that recursive algorithms do a lot of method calling.
As we saw in our various traces, each time a method is called, a representation of the method call is placed on the method call stack. These often take the form of a block of memory locations, which can be quite large. The block must contain space for the method’s local variables, including its parameters. Also, unless the method is void, the block must contain space for the method’s return value. In addition it must contain a reference to the calling method, so it will know where to go when it is done. Figure below shows what the method call block would look like for the search() method.
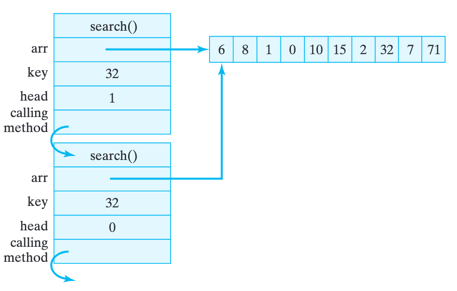
Recursion Call Stack after two levels of recursion
In addition to the memory required, a method call also requires extra CPU time. Each time a method is called, Java must create a method call block, copy the method call arguments to the parameters in the block, create initial values for any local variables that are used by the method, and fill in the return address of the calling method. All of this takes time, and in the case of a recursive method, these steps are repeated at each level of the recursion.
Compare these memory and CPU requirements with what normally transpires for an iterative algorithm—an algorithm involving a loop. The loop structure usually occurs entirely within a method, so it doesn’t incur either the memory or CPU overhead involved in recursion. Therefore, iterative algorithms are generally more efficient than recursive algorithms. One useful guideline, then, is when runtime performance and efficiency are of prime importance, you should use iteration instead of recursion.
On the other hand, recursive algorithms are much easier to design than the corresponding iterative algorithms for many problems. We tried to illustrate this point in our development of the Sierpinski gasket algorithm, but there are many other examples that we could have used.
Given that developer time and productivity are the most expensive resource involved in software development, a recursive solution may be easier to develop and maintain than a corresponding iterative solution. And given the great cost of software development, a less efficient solution that is easier to develop, easier to understand, and easier to maintain may be preferable to a highly efficient algorithm that’s difficult to understand. For some problems then, such as the Sierpinski gasket, a recursive algorithm may provide the best solution.
One final point that’s worth making is that some optimizing compilers are able to convert recursive methods into iterative methods when they compile the program. The algorithms for doing this are well known. They are often subjects for study in a data structures course, so we won’t go into them here. The resulting runtime programs will be just as efficient, in CPU time and memory, as if you had written iterative methods. The point is that if you have such a compiler, you really get the best of both worlds. You get the advantage of using recursion as a problem-solving and software development approach, and the compiler takes care of producing an efficient object program.