
For many software developers, release days are stressful events. There’s always some risk that things might go wrong in the process or that a bug would surface in production. At my previous company, we had a manual release process that was very human intensive; hence, error prone. On release days, DevOps would load binaries on a staging environment and perform user acceptance tests (UAT) manually. If the tests were successful, the software was copied to production servers and verified with smoke tests and occasionally, a trimmed down version of the UAT was run again. Here are the common problems we faced:
- 2 out 3 times when we had to roll back a release because of an issue, it was due to a configuration mismatch between staging and production environments.
- The release process was slow and it took a long time to put new features in the hands of our users. It wasn’t uncommon for the release process to take days or sometimes even weeks.
- The slow release process and the manual UAT had another side-effect: the developers didn’t get timely feedback. By the time feedback arrived, they were often in the middle of another feature. This incurred additional overhead because their memories were no longer fresh and on rare occasions, the error got re-introduced due to mix-up between branches.
In short, manual and ad-hoc release processes are suboptimal and the release day is fraught with stress. In our case, it was tolerable until releases became more frequent and the team grew. To improve and automate the release process, there’s a software engineering approach know as Continuous Delivery (CD).
Continuous delivery makes it possible to release new features quickly and reliably. It provides fast feedback to developers. The software is built in a way where it can be automatically and safely released to production at any time. This is ensured by delivering every change to a production-like environment and running extensive automated tests on it. According to Martin Fowler, you are doing continuous delivery if:
[…] a business sponsor could request that the current development version of the software can be deployed into production at a moment’s notice - and nobody would bat an eyelid, let alone panic.
Continuous delivery has a pre-requisite known as Continuous Integration (CI). CI is an Extreme Programming practice which requires that the new changes are integrated into the main branch as soon as they are finished so that the project is always kept in a working state. Usually, it works like this: developers commit their changes to GitHub (or another VCS) which triggers the build process. The entire application along with the required dependencies is built and a comprehensive set of unit and integration tests are run against it. If the tests fail, the team stops working and fixes the issue until the software is in working state again. Without CI, integration can very easily become a nightmare. Continuous integration is great and it’s one of the very first things I do when starting a new project.
I have seen many examples where teams stop paying attention to broken builds. This usually happens when the CI process becomes a big, hairy beast. This defeats the main goal of CI: broken builds should never be ignored and fixing them should be the top priority for the team. To ensure that it happens, the CI process should be kept short, sweet and simple. If tests take too long to run, are unreliable or can’t help pin-point the problem, the team will quickly stop paying attention to the broken builds or even worse, finger-pointing like “the other project broke the build” will ensue in dysfunctional teams.
Continuous integration is mainly focused on development teams. It’s possible to have CI with a manual release process. In our case, we had CI but the binaries and corresponding configuration files were manually copied to staging and production environments. In contrast, the continuous delivery automates the release process end-to-end. To achieve that goal, it uses a pipeline with distinct stages and their associated processes.
A continuous delivery pipeline is a manifestation of your release process for getting a new release out of the door. According to Martin Fowler:
One of the challenges of an automated build and test environment is you want your build to be fast, so that you can get fast feedback, but comprehensive tests take a long time to run. A deployment pipeline is a way to deal with this by breaking up your build into stages. Each stage provides increasing confidence, usually at the cost of extra time. Early stages can find most problems yielding faster feedback, while later stages provide slower and more through probing. Deployment pipelines are a central part of ContinuousDelivery.
A typical CD pipeline might look like the following:
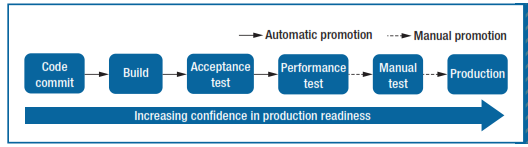
A crucial part that determines the success of CD pipelines is well-written acceptance tests that are run in the later stages of the pipeline for “more through probing”. They ensure that the software satisfies user requirements and specifications. Acceptance tests should not be exposed to internal system details and should treat it like a black-box. Our acceptance tests consisted of input that a real user would provide and the tests received and checked the system’s output to verify that it matches expectation.
Transition from one stage to the next in the CD pipeline could be automatic or manual. Manual doesn’t imply copying artifacts manually to the next stage. It means that someone needs to signal the system that it’s okay to transition to the next stage usually at a push of a button.
Continuous delivery pipelines are modeled after delivery processes. There’s no right way: one pipeline may look very different from another. For example, in an SOA project with many stand-alone components, we decided that a single pipeline for all the components was the best solution. Another project required individual pipelines for each component (microservice). The integration pipeline, shown in the picture below.
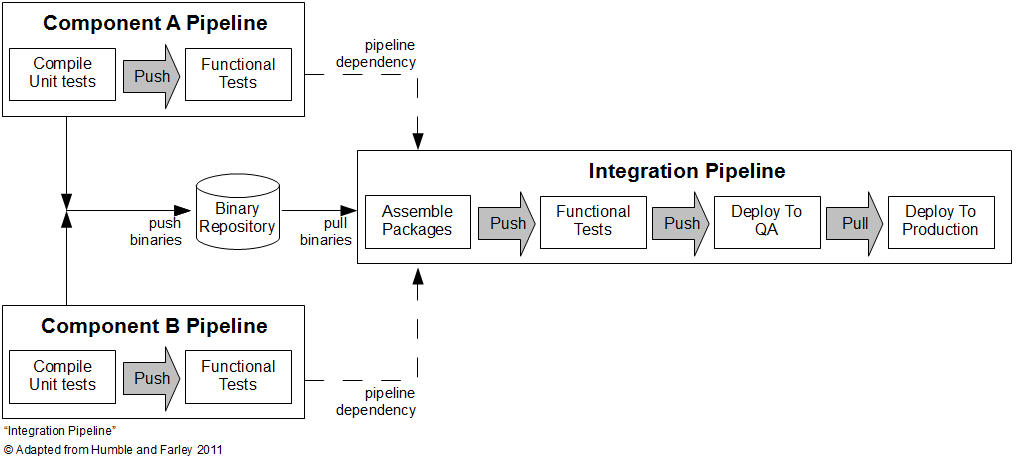
Implementing a good continuous delivery pipeline can be a daunting task but yields great benefits if done right. In my opinion, the best way is to carefully study your deployment process, understand all the dependencies, get buy-in from the team and start with something small and simple.
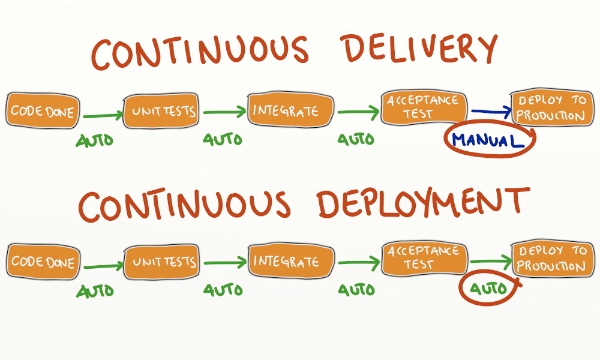
Continuous Delivery vs Continuous Deployment
In continuous delivery, a human makes the final call to deploy the release to production environment. Typically, the release to production happens several changes later or at some fixed date.
Continuous deployment evolves the continuous delivery process one step further: every change that happens to pass automated tests is deployed to production automatically. Continuous deployment may not be right for every project and even though it sounds great in theory, and I’m sure it is, I’ve not really tried it in a commercial project.
Here’s a nice picture comparing the continuous delivery and deployment processes taken from Yassal Sundman’s blog:
As far as continuous delivery tools are concerned, I don’t have a personal preference. I’ve recently started using AWS CodePipeline (along with AWS CodeDeploy) to automate the delivery process on the AWS cloud and I’m generally satisfied with it.