
Amazon DynamoDB supports Auto Scaling which is a fantastic feature.
When enabled, Auto Scaling adjusts read and write capacities of DynamoDB tables (and global secondary indexes) automatically based on the demand. If you haven’t used DynamoDB before, you might be wondering why is this important? Before Auto Scaling, the users were required to provide fixed capacities for their tables. These capacities were static and didn’t respond to traffic demands. This was problematic because:
- The application performance and high-availability was compromised whenever the utilization exceeded the provisioned throughput. When this happened, DynamoDB throttled requests, which resulted in loss of data or poor user experience.
- Cost control was poor at best. DynamoDB charges you by how much you provision. You end up paying the full cost by provisioned amounts, even if you use less than what you provisioned. In other words, if you overprovision for peak load, you’ll pay extra during the non-peak hours, when the capacity isn’t being full utilized. On the other hand, if you underprovision, the performance of your application will suffer due to throttling when the load exceeds the provisioned capacity.
Many real-world use cases are difficult to predict in advance and fluctuations are common. Speaking of traffic fluctuations, they are prevalent and hard to deal with. In mobile gaming, the traffic can increase suddenly if Apple or Google features the game, or the publisher runs a massive ad campaign. A website can suddenly see a large number of visitors if an article is picked up by a major newspaper or news aggregator site.
- What is DynamoDB Auto Scaling?
- DynamoDB Auto Scaling Pricing
- DynamoDB Auto Scaling vs On Demand
- DynamoDB and DAX
What is DynamoDB Auto Scaling?
DynamoDB Auto Scaling feature lets you automatically manage throughput in response to your traffic patterns without throttling your users. You can assign minimum and maximum provisioned capacities to a table (or Global Secondary Index). When the traffic goes up, the table will increase its provisioned read and write capacity. When the traffic goes down, it will decrease the throughput so that you don’t pay for unused provisioned capacity.
Historical Perspective
Before Auto Scaling feature was introduced in 2017 (fun fact: I was there at the re:Invent when they announced it), it was challenging for Engineering and DevOps teams to keep track of and keep up with manually adjusting provisioning in response to external events. I worked in a team where this was a huge challenge. If you overprovision, you can end up paying thousands of dollars for unused capacity. People came up with custom solutions like Lambda scripts, sometimes even adding a cache to reduce calls to DynamoDB during peak load (Caching has other uses as well.) Then there were third-party solutions as well. Dynamic DynamoDB was arguably the most widely used. It’s open-source and has additional features such as time-based auto scaling and granular control over how many read and write capacity units to add or remove during auto scale up or down. However, now that this feature is built-in to DynamoDB and enabled by default, I doubt that third-party solutions will be used very much, if at all. So long and thanks for all the fish.
Auto Scaling is an optional feature and you must enable it explicitly using the ‘Auto Scaling’ settings in the AWS Console, as shown in the image below. You may also enable this using AWS SDK.
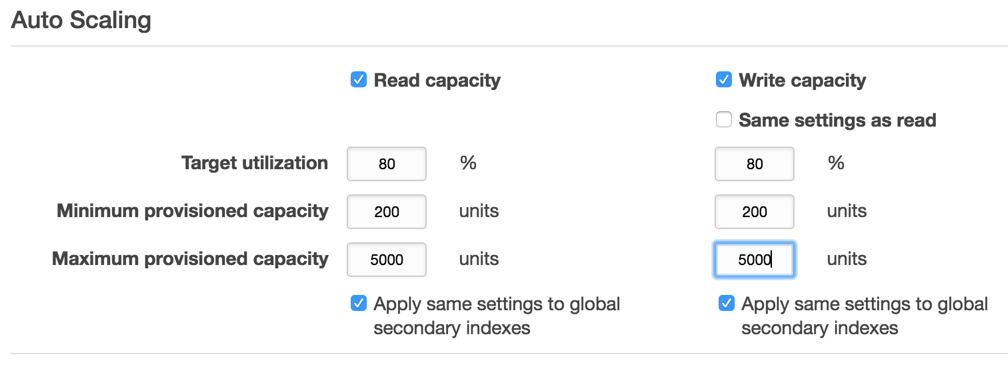
Auto Scale Target Utilization
In the image above, I’m specifying that the table utilization (target utilization) is kept at 80%. If the utilization exceeds this threshold, auto-scaling will increase the provisioned read capacity. Likewise, if the utilization falls below 80%, it will decrease the capacity to reduce unnecessary costs. In other words, auto-scaling uses an algorithm to adjust the provisioned throughput of the table so that the actual utilization remains at or near your target utilization.
Target utilization is useful to deal with sudden increases in traffic. Why? Because auto-scaling doesn’t kick in and take effect instantly. It takes time (~5 to 10 minutes to take effect.) If you set target utilization to a very number e.g. 100%, the benefit you’d get is that you’d always pay for used capacity. The drawback is that if the demand on the table increases suddenly, you’ll likely see throttling errors while DynamoDB auto scaling adjusts capacities and increase to match demand after you run out of your burst capacity quota. As a general rule of thumb, 70%-75% is a good number.
DynamoDB Auto Scaling Pricing
There is no additional cost to use DynamoDB Auto Scaling. You only pay for the provisioned capacity, which auto scaling will adjust for you in response to traffic patterns. If you do it right, auto scaling will reduce costs and ensure you don’t pay for unused capacity. One important thing to keep in mind is not to set the maximum provisioned capacity too high. Because if you do, you risk scaling all the way up to that capacity and be responsible for costs. Estimate what’s the maximum cost you could bear, and then set maximum capacity accordingly.
DynamoDB Auto Scaling vs On Demand
DynamoDB On-Demand is a related feature for managing throughput of a table. With On-Demand, you do not do any capacity planning or provisioning. You don’t specify read or write capacities anywhere. None, Nada, Zilch. Instead, you only pay for what you use. On-Demand was introduced in 2018, a year after Auto Scaling was launched.
On-Demand sounds too good to be true. If you think about it, why would anyone ever use Auto Scaling if On-Demand is available? Is there a catch?
Yes, there’s a catch. It’s cost. On-Demand is more expensive than Auto Scaling (provisioned capacity.)
- On-Demand: Cost for 1 million write requests is $1.25
- Provisioned Capacity: Cost for 1 million write requests is roughly $0.20
On Demand is about 6 times more expensive than provisioned capacity.
When to use Auto Scaling vs On Demand?
Auto Scaling works great when you have predictable traffic patterns or if you can approximate based on historical data. The other reason for using provisioned capacity is cost. At my last company, DynamoDB was our main database and cost control was a constant challenge. As much as I loved On-Demand, I couldn’t justify the 6x cost. Besides, Auto Scale works really well in most scenarios. The only time we had issues was when there was a sudden traffic spike (in game event) but that was a problem across the infrastructure not just DynamoDB. Another downside of On-Demand is the unexpected bill due to huge traffic increase. I’m not aware of a way to control this at the moment.
On the other hand, if the traffic volume is low and the traffic patterns are unknown, On-Demand might make perfect sense. For example, if you estimate doing a max of 1 million requests a month, $1.25 vs. $0.18 a month doesn’t really make that much of a difference.
DynamoDB and DAX
Jeff Barr wrote a blog post introducing the new feature and has screenshots of CloudWatch graphs. Check it out if you want to learn more. One key takeaway from his blog is that auto scaling isn’t ideal for bursts:
DynamoDB Auto Scaling is designed to accommodate request rates that vary in a somewhat predictable, generally periodic fashion. If you need to accommodate unpredictable bursts of reading activity, you should use Auto Scaling in combination with DAX (read Amazon DynamoDB Accelerator (DAX) – In-Memory Caching for Read-Intensive Workloads to learn more).
If you enjoyed this post, please share using the social sharing icons below. It’ll help CodeAhoy grow and every share counts. Thank you!
 AI Is Not Magic. How Neural Networks Learn
AI Is Not Magic. How Neural Networks Learn
Comments (1)
Marcos Santanna
I’m studying for CSAA01 and this article helps me a lot. Thank you !