Distributed Caching at the Web Scale and Its Challenges
Today’s web applications and social networks are serving billions of users around the globe. These users generate billions of key lookups and millions of data object updates per second. A single user’s social network page load requires hundreds of key lookups.
This scale creates many design challenges for the underlying storage systems.
First, these systems have to serve user requests with low latency. Any increase in the request latency leads to a decrease in user interest.
Second, storage systems have to be highly available. Failures should be handled seamlessly without affecting user requests. Third, users consume an order of magnitude more data than they produce. Therefore, storage systems have to be optimized for read-intensive workloads. To address these challenges, distributed in-memory caching services have been widely deployed on top of persistent storage.In this tutorial, we survey the recent developments in distributed caching services. We present the algorithmic and architectural efforts behind these systems focusing on the challenges in addition to open research questions.
What Are Distributed Caching Services And Why We Need Them?
During the past decade, social networks have attracted hundreds of millions of users. These users share their relationships, read news, and exchange images and videos in a timely personalized experience. To enable this real-time personalized experience, the underlying storage systems have to provide efficient, scalable, highly available access to big data. Social network users consume an order of magnitude more data than they produce. In addition, a single page load requires hundreds of object lookups that should be served in a fraction of a second. Therefore, traditional disk-based storage systems are not suitable to handle requests at this scale due to the high access latency of disks and I/O throughput bounds.
To overcome these limitations, distributed caching services have been widely deployed on top of persistent storage in order to efficiently serve user requests at scale. Akamai and other CDNs use distributed caching to bring data closer to the users and to reduce access latency. Memcached and Redis are two distributed open source cache implementations that are widely adopted in the cloud and social networks. The default implementations of Memcached uses the Least Recently Used (LRU) cache replacement policy. Although LRU is simple and easy to implement, it might not achieve the highest cache hit rates for some deployments. Increasing the hit rate by 1% can save up to 35% of the average read latency. Therefore, much effort has focused on developing better caching policies that achieve higher cache hit rates.
Teams in Facebook and Twitter have focused on the architectural challenges of distributed caching at scale. Sharding, replication, request batching, load balancing, hierarchical caching, data access skewness, geo-replication, replica consistency, data updates, and cache invalidation are examples of the architectural challenges for distributed caching and current implementations address some of these challenges.
In this tutorial, we present the data access model. Then, we summarize the recent efforts on cache replacement policies at a single server level. Finally, we present real deployed systems at a data center scale.
Distributed Caching Use Case and Example
We assume millions of end-users sending streams of page-load and page-update requests to hundreds of stateless application servers as shown in the figure below.
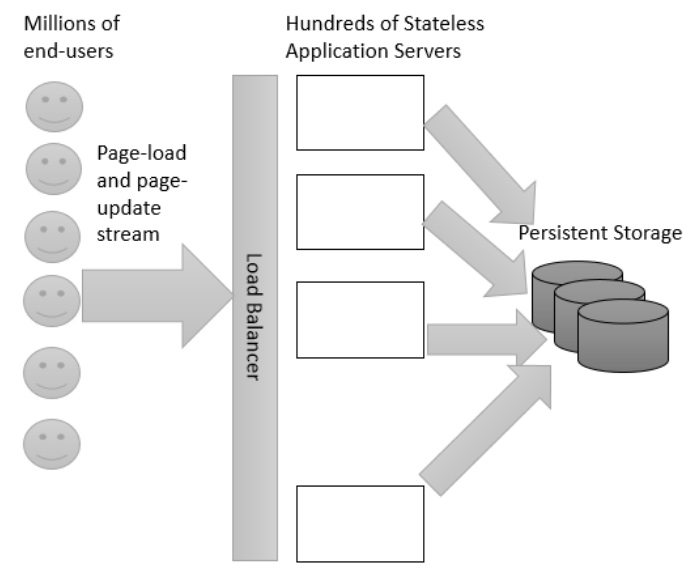
Large scale web system model without caching.
Application servers hide the storage details from the clients and reduce the number of connections handled by the storage system. Each request is translated to hundreds of key lookups and updates. As traditional disk-based systems cannot efficiently handle user requests at scale, caching services have been widely used to enhance the performance of web applications by alleviating the number of requests sent to the persistent storage. The ultimate objective of caching services is to achieve a high hit-rate because the latency of a cache miss is usually few orders of magnitude more than a cache hit.
Therefore, designing a caching service to serve a very large key space using commodity machines introduces many challenges:
First, the key space is too large and serving the whole key space using a single machine violates cache locality and increases the miss-rate. To overcome this problem, designers shard the key space into multiple partitions using either range or hash partitioning and use distributed caching servers to serve different shards.
Second, the key space, even after sharding, is too large to fit in memory of commodity servers. Therefore, a cache replacement policy (e.g. LRU, FIFO, LIFO, Random etc) has to be carefully designed to achieve high hit-rates without adding a significant bookkeeping overhead. Also, policies should avoid using shared data structures between threads to reduce contentions.
Third, commodity machines can fail and replication is needed to distribute the workload and achieve high availability. Figure below shows an abstract model for a distributed caching service where each caching server is serving a specific shard and each shard is served by multiple replicas.
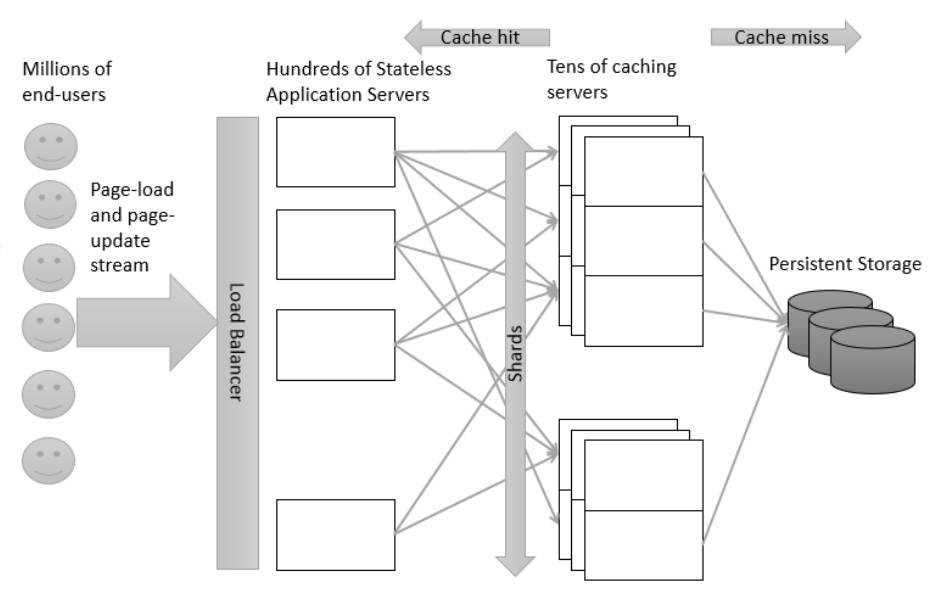
Large scale web system model with caching.
Replacement policy-base solutions
Memcached and Redis are two widely adopted open source implementations for distributed caching services. Memcached provides a simple Set, Get,and Delete interface for only string keys and values while Redis also supports other data types. Cloud providers have adopted Memcached and Redis and provide customized/hosted versions of both as services for their clients (E.g Elasticache by AWS). Both Memcached and Redis supports the LRU cache replacement policy which tracks the time of access of each key in the cache. Other efforts enhance the performance by introducing more tracking per key access or by sharding the hash table and the tracking data structures to reduce the contention between threads and avoid global synchronization. Adaptive Re-placement Cache ARC tracks the recency and the frequency of access in addition to the recency of key eviction to decide which key should be evicted next. To reduce thread contention, Memcached divides the memory into slabs for different object sizes and each slab maintains its tracking information independently.
Distributed Caching at Facebook and Twitter
Facebook and Twitter use distributed version of Memcached. Facebook scaled Memcached by partitioning the key space into different pools. Each pool is served by multiple replicas to tolerate failures and distribute the lookup workload. Both Twitter and Facebook implementations batch requests in a client proxy to reduce the number of requests sent to the server. Invalidation messages are sent from the persistent storage to the cache replica to invalidate the stale values. Facebook and Twitter use Memcached as a look-aside cache.
However, Memcached is not optimized to capture a graph storage model. Therefore, Facebook built Tao, a distributed caching service optimized for graph storage models. In Tao, nodes and their associations are served from the same caching server. Tao uses storage and caching geo-replication to overcome a data-center scale outage. Updates go to the master storage replica through a cache leader server which is responsible for all the updates and the invalidation messages for all the data items in its shard. In Tao, heavy hitters (hot data objects) are handled by introducing hierarchical caching where heavy hitters are cached in the upper hierarchy. Both Tao and Memcached at Facebook support eventual consistency between the replicas.The current systems have addressed many of the distributed caching challenges.
However, challenges like 1) data access skewness, 2) dynamical changes in access pattern, 3) providing stronger guarantees of replica consistency, and 4) providing consistency between multiple data representations ares till open research questions that require innovative algorithmic and architectural solutions to provide these guarantees at scale.
(C) CodeAhoy. Licensed under CC BY-SA 4.0.
Original content Caching at the Web Scale Used under Creative Commons Attribution License CC-BY 4.0. Edits: 1) Changed heading 2) Restructured content and sentences 3) Added some links.