Related Books





Books / Introduction to C Programming Language / Chapter 42
Graphs
In this chapter, we’ll cover implementing graphs and graph algorithms in C.
Basic definitions
A graph consists of a set of nodes or vertices together with a set of edges or arcs where each edge joins two vertices. Unless otherwise specified, a graph is undirected: each edge is an unordered pair {u, v} of vertices, and we don’t regard either of the two vertices as having a distinct role from the other. However, it is more common in computing to consider directed graphs or digraphs in which edges are ordered pairs (u, v); here the vertex u is the source of the edge and vertex v is the sink or target of the edge. Directed edges are usually drawn as arrows and undirected edges as curves or line segments. It is always possible to represent an undirected graph as a directed graph where each undirected edge {u, v} becomes two oppositely directed edges (u, v) and (v, u).
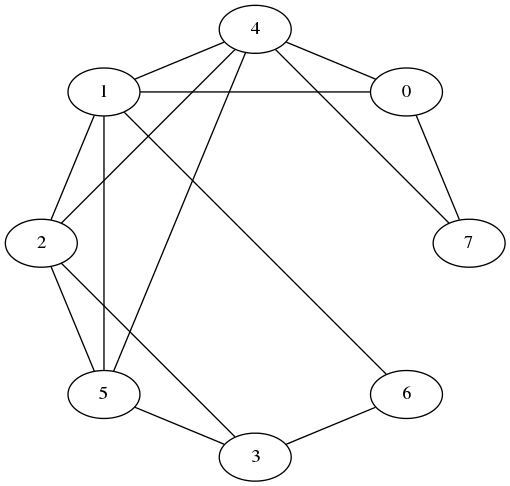
Here is an example of a small graph:
Here is a similar directed graph:
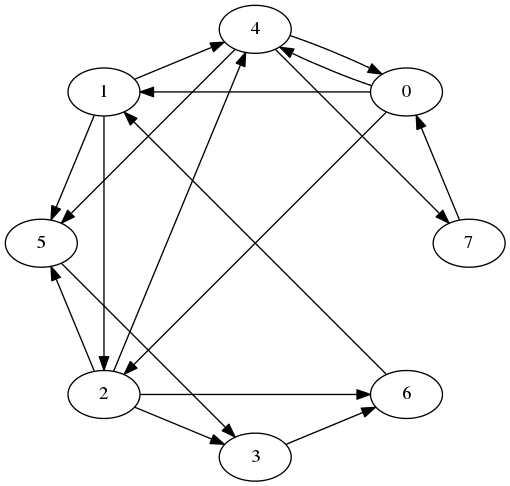
Given an edge (u, v), the vertices u and v are said to be incident to the edge and adjacent to each other. The number of vertices adjacent to a given vertex u is the degree of u; this can be divided into the out-degree (number of vertices v such that (u, v) is an edge) and the in-degree (number of vertices v such that (v, u) is an edge). A vertex v adjacent to u is called a neighbor of u, and (in a directed graph) is a predecessor of u if (v, u) is an edge and a successor of u if (u, v) is an edge. We will allow a node to be its own predecessor and successor.
Why graphs are useful
Graphs can be used to model any situation where we have things that are related to each other in pairs; for example, all of the following can be represented by graphs:
Family trees
Nodes are members, with an edge from each parent to each of their children.
Transportation networks
Nodes are airports, intersections, ports, etc. Edges are airline flights, one-way roads, shipping routes, etc.
Assignments
Suppose we are assigning classes to classrooms. Let each node be either a class or a classroom, and put an edge from a class to a classroom if the class is assigned to that room. This is an example of a bipartite graph, where the nodes can be divided into two sets S and T and all edges go from S to T.
Operations on graphs
What would we like to do to graphs? Generally, we first have to build a graph by starting with a set of nodes and adding in any edges we need, and then we want to extract information from it, such as “Is this graph connected?”, “What is the shortest path in this graph from s to t?”, or “How many edges can I remove from this graph before some nodes become unreachable from other nodes?” There are standard algorithms for answering all of these questions; the information these algorithms need is typically (a) given a vertex u, what successors does it have; and sometimes (b) given vertices u and v, does the edge (u, v) exist in the graph?
Representations of graphs
A good graph representation will allow us to answer one or both of these questions quickly. There are generally two standard representations of graphs that are used in graph algorithms, depending on which question is more important.
For both representations, we simplify the representation task by insisting that vertices be labeled 0, 1, 2, …, n − 1, where n is the number of vertices in the graph. If we have a graph with different vertex labels (say, airport codes), we can enforce an integer labeling by a preprocessing step where we assign integer labels, and then translate the integer labels back into more useful user labels afterwards. The preprocessing step can usually be done using a hash table in O(n) time, which is likely to be smaller than the cost of whatever algorithm we are running on our graph, and the savings in code complexity and running time from working with just integer labels will pay this cost back many times over.
Adjacency matrices
An adjacency matrix is just a matrix a where a[i][j] is 1 if (i,j) is an edge in the graph and 0 otherwise. It’s easy to build an adjacency matrix, and adding or testing for the existence of an edges takes O(1) time. The downsides of adjacency matrices are that finding all the outgoing edges from a vertex takes O(n) time even if there aren’t very many, and the O(n2) space cost is high for “sparse graphs,” those with much fewer than n2 edges.
Adjacency lists
An adjacency list representation of a graph creates a list of successors for each node u. These lists may be represented as linked lists (the typical assumption in algorithms textbooks), or in languages like C may be represented by variable-length arrays. The cost for adding an edge is still O(1), but testing for the existence of an edge (u, v) rises to O(d+(u)), where d+(u) is the out-degree of u (i.e., the length of the list of u’s successors). The cost of enumerating the successors of u is also O(d+(u)), which is clearly the best possible since it takes that long just to write them all down. Finding predecessors of a node u is extremely expensive, requiring looking through every list of every node in time O(n + m), where m is the total number of edges, although if this is something we actually need to do often we can store a second copy of the graph with the edges reversed.
Adjacency lists are thus most useful when we mostly want to enumerate outgoing edges of each node. This is common in search tasks, where we want to find a path from one node to another or compute the distances between pairs of nodes. If other operations are important, we can optimize them by augmenting the adjacency list representation; for example, using sorted arrays for the adjacency lists reduces the cost of edge existence testing to O(log (d+(u))), and adding a second copy of the graph with reversed edges lets us find all predecessors of u in O(d−(u)) time, where d−(u) is u’s in-degree.
Adjacency lists also require much less space than adjacency matrices for sparse graphs: O(n + m) vs O(n2) for adjacency matrices. For this reason adjacency lists are more commonly used than adjacency matrices.
An implementation
Here is an implementation of a basic graph type using adjacency lists.
/* basic directed graph type */
typedef struct graph *Graph;
/* create a new graph with n vertices labeled 0..n-1 and no edges */
Graph graphCreate(int n);
/* free all space used by graph */
void graphDestroy(Graph);
/* add an edge to an existing graph */
/* doing this more than once may have unpredictable results */
void graphAddEdge(Graph, int source, int sink);
/* return the number of vertices/edges in the graph */
int graphVertexCount(Graph);
int graphEdgeCount(Graph);
/* return the out-degree of a vertex */
int graphOutDegree(Graph, int source);
/* return 1 if edge (source, sink) exists), 0 otherwise */
int graphHasEdge(Graph, int source, int sink);
/* invoke f on all edges (u,v) with source u */
/* supplying data as final parameter to f */
/* no particular order is guaranteed */
void graphForeach(Graph g, int source,
void (*f)(Graph g, int source, int sink, void *data),
void *data);
#include <stdlib.h>
#include <assert.h>
#include "graph.h"
/* basic directed graph type */
/* the implementation uses adjacency lists
* represented as variable-length arrays */
/* these arrays may or may not be sorted: if one gets long enough
* and you call graphHasEdge on its source, it will be */
struct graph {
int n; /* number of vertices */
int m; /* number of edges */
struct successors {
int d; /* number of successors */
int len; /* number of slots in array */
int isSorted; /* true if list is already sorted */
int list[]; /* actual list of successors starts here */
} *alist[];
};
/* create a new graph with n vertices labeled 0..n-1 and no edges */
Graph
graphCreate(int n)
{
Graph g;
int i;
g = malloc(sizeof(struct graph) + sizeof(struct successors *) * n);
assert(g);
g->n = n;
g->m = 0;
for(i = 0; i < n; i++) {
g->alist[i] = malloc(sizeof(struct successors));
assert(g->alist[i]);
g->alist[i]->d = 0;
g->alist[i]->len = 0;
g->alist[i]->isSorted= 1;
}
return g;
}
/* free all space used by graph */
void
graphDestroy(Graph g)
{
int i;
for(i = 0; i < g->n; i++) free(g->alist[i]);
free(g);
}
/* add an edge to an existing graph */
void
graphAddEdge(Graph g, int u, int v)
{
assert(u >= 0);
assert(u < g->n);
assert(v >= 0);
assert(v < g->n);
/* do we need to grow the list? */
while(g->alist[u]->d >= g->alist[u]->len) {
g->alist[u]->len = g->alist[u]->len * 2 + 1; /* +1 because it might have been 0 */
g->alist[u] =
realloc(g->alist[u],
sizeof(struct successors) + sizeof(int) * g->alist[u]->len);
}
/* now add the new sink */
g->alist[u]->list[g->alist[u]->d++] = v;
g->alist[u]->isSorted = 0;
/* bump edge count */
g->m++;
}
/* return the number of vertices in the graph */
int
graphVertexCount(Graph g)
{
return g->n;
}
/* return the number of vertices in the graph */
int
graphEdgeCount(Graph g)
{
return g->m;
}
/* return the out-degree of a vertex */
int
graphOutDegree(Graph g, int source)
{
assert(source >= 0);
assert(source < g->n);
return g->alist[source]->d;
}
/* when we are willing to call bsearch */
#define BSEARCH_THRESHOLD (10)
static int
intcmp(const void *a, const void *b)
{
return *((const int *) a) - *((const int *) b);
}
/* return 1 if edge (source, sink) exists), 0 otherwise */
int
graphHasEdge(Graph g, int source, int sink)
{
int i;
assert(source >= 0);
assert(source < g->n);
assert(sink >= 0);
assert(sink < g->n);
if(graphOutDegree(g, source) >= BSEARCH_THRESHOLD) {
/* make sure it is sorted */
if(! g->alist[source]->isSorted) {
qsort(g->alist[source]->list,
g->alist[source]->d,
sizeof(int),
intcmp);
}
/* call bsearch to do binary search for us */
return
bsearch(&sink,
g->alist[source]->list,
g->alist[source]->d,
sizeof(int),
intcmp)
!= 0;
} else {
/* just do a simple linear search */
/* we could call lfind for this, but why bother? */
for(i = 0; i < g->alist[source]->d; i++) {
if(g->alist[source]->list[i] == sink) return 1;
}
/* else */
return 0;
}
}
/* invoke f on all edges (u,v) with source u */
/* supplying data as final parameter to f */
void
graphForeach(Graph g, int source,
void (*f)(Graph g, int source, int sink, void *data),
void *data)
{
int i;
assert(source >= 0);
assert(source < g->n);
for(i = 0; i < g->alist[source]->d; i++) {
f(g, source, g->alist[source]->list[i], data);
}
}
And here is some test code: graphTest.c.
5.14.4.3 Implicit representations
For some graphs, it may not make sense to represent them explicitly. An example might be the word-search graph from, which consists of all words in a dictionary with an edge between any two words that differ only by one letter. In such a case, rather than building an explicit data structure containing all the edges, we might generate edges as needed when computing the neighbors of a particular vertex. This gives us an implicit or procedural representation of a graph.
Implicit representations require the ability to return a vector or list of values from the neighborhood-computing function. There are various way to do this, of which the most sophisticated might be to use an iterator.
Searching for paths in a graph
A path is a sequence of vertices v1, v2, …vk where each pair (vi, vi + 1) is an edge. Often we want to find a path from a source vertex s to a target vertex t, or more generally to detect which vertices are reachable from a given source vertex s. We can solve these problems by using any of several standard graph search algorithms, of which the simplest and most commonly used are depth-first search and breadth-first search.
Depth First Search
Both of these search algorithms are a special case of a more general algorithm for growing a directed tree in a graph rooted at a given node s. Here we are using tree as a graph theorist would, to mean any set of k nodes joined by k − 1 edges. This is similar to trees used in data structures except that there are no limits on the number of children a node can have and no ordering constraints within the tree.
The general tree-growing algorithm might be described as follows:
- Start with a tree consisting of just s.
- If there is at least one edge that leaves the tree (i.e. goes from a node in the current tree to a node outside the current tree), pick the “best” such edge and add it and its sink to the tree.
- Repeat step 2 until no edges leave the tree.
Practically, steps 2 and 3 are implemented by having some sort of data structure that acts as a bucket for unprocessed edges. When a new node is added to the tree, all of its outgoing edges are thrown into the bucket. The “best” outgoing edge is obtained by applying some sort of pop, dequeue, or delete-min operation to the bucket, depending on which it provides; if this edge turns out to be an internal edge of the tree (maybe we added its sink after putting it in the bucket), we throw it away. Otherwise we mark the edge and its sink as belonging to the tree and repeat.
The output of the generic tree-growing algorithm typically consists of (a) marks on all the nodes that are reachable from s, and (b) for each such node v, a parent pointer back to the source of the edge that brought v into the tree. Often these two values can be combined by using a null parent pointer to represent the absence of a mark (this usually requires making the root point to itself so that we know it’s in the tree). Other values that may be useful are a table showing the order in which nodes were added to the tree.
What kind of tree we get depends on what we use for the bucket—specifically, on what edge is returned when we ask for the “best” edge. Two easy cases are:
- The bucket is a stack. When we ask for an outgoing edge, we get the last edge inserted. This has the effect of running along as far as possible through the graph before backtracking, since we always keep going from the last node if possible. The resulting algorithm is called depth-first search and yields a depth-first search tree. If we don’t care about the lengths of the paths we consider, depth-first search is a perfectly good algorithm for testing connectivity. It can also be implemented without any auxiliary data structures as a recursive procedure, as long as we don’t go so deep as to blow out the system stack.
- The bucket is a queue. Now when we ask for an outgoing edge, we get the first edge inserted. This favors edges that are close to the root: we don’t start consider edges from nodes adjacent to the root until we have already added all the root’s successors to the tree, and similarly we don’t start considering edges at distance k until we have already added all the closer nodes to the tree. This gives breadth-first search, which constructs a shortest-path tree in which every path from the root to a node in the tree has the minimum length.
Structurally, these algorithms are almost completely identical; indeed, if we organize the stack/queue so that it can pop from both ends, we can switch between depth-first search and breadth-first search just by choosing which end to pop from.
Below, we give a combined implementation of both depth-first search and breadth-first search that does precisely this, although this is mostly for show. Typical implementations of breadth-first search include a further optimization, where we test an edge to see if we should add it to the tree (and possibly add it) before inserting into the queue. This gives the same result as the DFS-like implementation but only requires O(n) space for the queue instead of O(m), with a smaller constant as well since don’t need to bother storing source edges in the queue. An example of this approach is given below.
The running time of any of these algorithms is very fast: we pay O(1) per vertex in setup costs and O(1) per edge during the search (assuming the input is in adjacency-list form), giving a linear O(n + m) total cost. Often it is more expensive to set up the graph in the first place than to run a search on it.
Implementation of depth-first and breadth-first search
Here is a simple implementation of depth-first search, using a recursive algorithm, and breadth-first search, using an iterative algorithm that maintains a queue of vertices. In both cases the algorithm is applied to a sample graph whose vertices are the integers 0 through n − 1 for some n, and in which vertex x has edges to vertices x/2, 3 ⋅ x, and x + 1, whenever these values are also integers in the range 0 through n − 1. For large graphs it may be safer to run an iterative version of DFS that uses an explicit stack instead of a possibly very deep recursion.
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <stdint.h>
typedef int Vertex;
#define VERTEX_NULL (-1)
struct node {
Vertex *neighbors; /* array of outgoing edges, terminated by VERTEX_NULL */
Vertex parent; /* for search */
};
struct graph {
size_t n; /* number of vertices */
struct node *v; /* list of vertices */
};
void
graphDestroy(struct graph *g)
{
Vertex v;
for(v = 0; v < g->n; v++) {
free(g->v[v].neighbors);
}
free(g);
}
/* this graph has edges from x to x+1, x to 3*x, and x to x/2 (when x is even) */
struct graph *
makeSampleGraph(size_t n)
{
struct graph *g;
Vertex v;
const int allocNeighbors = 4;
int i;
g = malloc(sizeof(*g));
assert(g);
g->n = n;
g->v = malloc(sizeof(struct node) * n);
assert(g->v);
for(v = 0; v < n; v++) {
g->v[v].parent = VERTEX_NULL;
/* fill in neighbors */
g->v[v].neighbors = malloc(sizeof(Vertex) * allocNeighbors);
i = 0;
if(v % 2 == 0) { g->v[v].neighbors[i++] = v/2; }
if(3*v < n) { g->v[v].neighbors[i++] = 3*v; }
if(v+1 < n) { g->v[v].neighbors[i++] = v+1; }
g->v[v].neighbors[i++] = VERTEX_NULL;
}
return g;
}
/* output graph in dot format */
void
printGraph(const struct graph *g)
{
Vertex u;
size_t i;
puts("digraph G {");
for(u = 0; u < g->n; u++) {
for(i = 0; g->v[u].neighbors[i] != VERTEX_NULL; i++) {
printf("%d -> %d;\n", u, g->v[u].neighbors[i]);
}
}
puts("}");
}
/* reconstruct path back to root from u */
void
printPath(const struct graph *g, Vertex u)
{
do {
printf(" %d", u);
u = g->v[u].parent;
} while(g->v[u].parent != u);
}
/* print the tree in dot format */
void
printTree(const struct graph *g)
{
Vertex u;
puts("digraph G {");
for(u = 0; u < g->n; u++) {
if(g->v[u].parent != VERTEX_NULL) {
printf("%d -> %d;\n", u, g->v[u].parent);
}
}
puts("}");
}
/* compute DFS tree starting at root */
/* this uses a recursive algorithm and will not work on large graphs! */
static void
dfsHelper(struct graph *g, Vertex parent, Vertex child)
{
int i;
Vertex neighbor;
if(g->v[child].parent == VERTEX_NULL) {
g->v[child].parent = parent;
for(i = 0; (neighbor = g->v[child].neighbors[i]) != VERTEX_NULL; i++) {
dfsHelper(g, child, neighbor);
}
}
}
void
dfs(struct graph *g, Vertex root)
{
dfsHelper(g, root, root);
}
/* compute BFS tree starting at root */
void
bfs(struct graph *g, Vertex root)
{
Vertex *q;
int head; /* deq from here */
int tail; /* enq from here */
Vertex current;
Vertex nbr;
int i;
q = malloc(sizeof(Vertex) * g->n);
assert(q);
head = tail = 0;
/* push root onto q */
g->v[root].parent = root;
q[tail++] = root;
while(head < tail) {
current = q[head++];
for(i = 0; (nbr = g->v[current].neighbors[i]) != VERTEX_NULL; i++) {
if(g->v[nbr].parent == VERTEX_NULL) {
/* haven't seen this guy */
/* push it */
g->v[nbr].parent = current;
q[tail++] = nbr;
}
}
}
free(q);
}
int
main(int argc, char **argv)
{
int n;
struct graph *g;
if(argc != 3) {
fprintf(stderr, "Usage: %s action n\nwhere action =\n g - print graph\n d - print dfs tree\n b - print bfs tree\n", argv[0]);
return 1;
}
n = atoi(argv[2]);
g = makeSampleGraph(n);
switch(argv[1][0]) {
case 'g':
printGraph(g);
break;
case 'd':
dfs(g, 0);
printTree(g);
break;
case 'b':
bfs(g, 0);
printTree(g);
break;
default:
fprintf(stderr, "%s: unknown action '%c'\n", argv[0], argv[1][0]);
return 1;
}
graphDestroy(g);
return 0;
}
The output of the program is either the graph, a DFS tree of the graph rooted at 0, or a BFS tree of the graph rooted at 0, in a format suitable for feeding to the GraphViz program dot, which draws pictures of graphs.
Here are the pictures for n = 20.
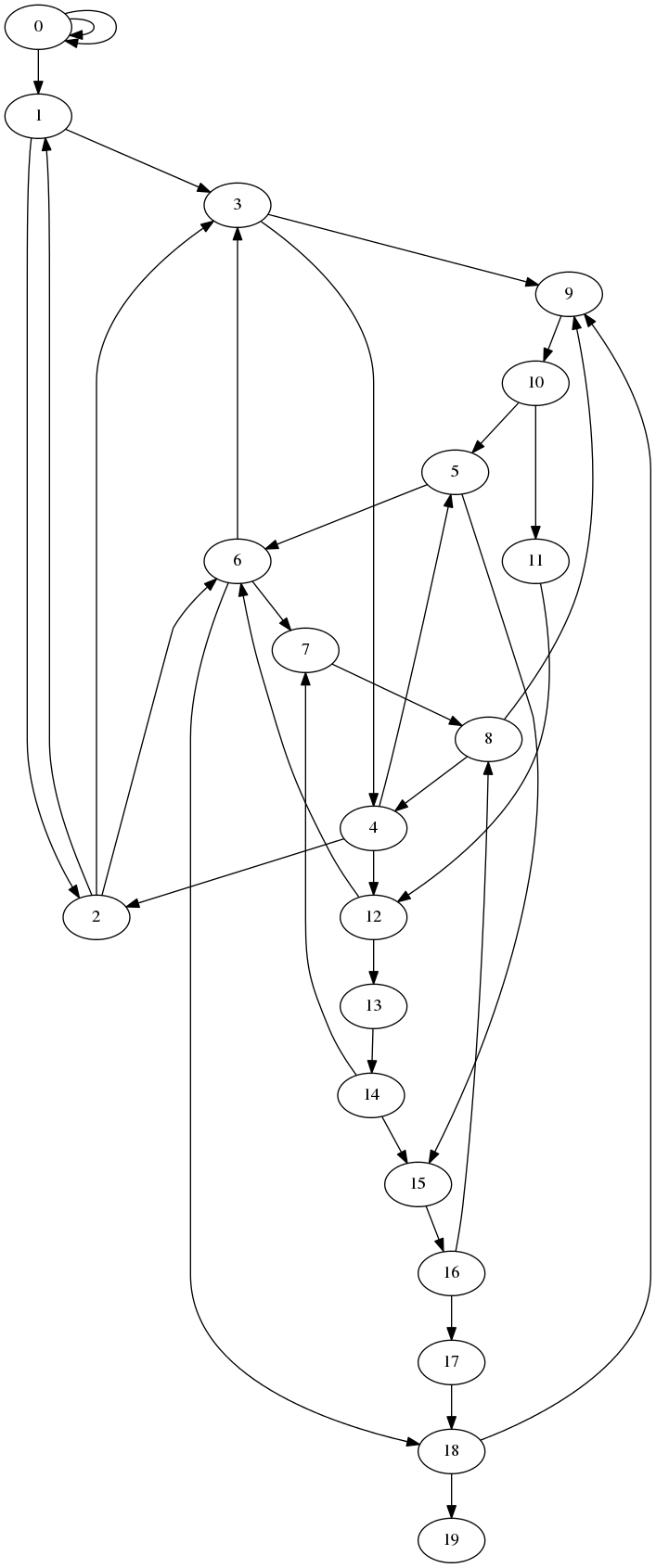
The full graph
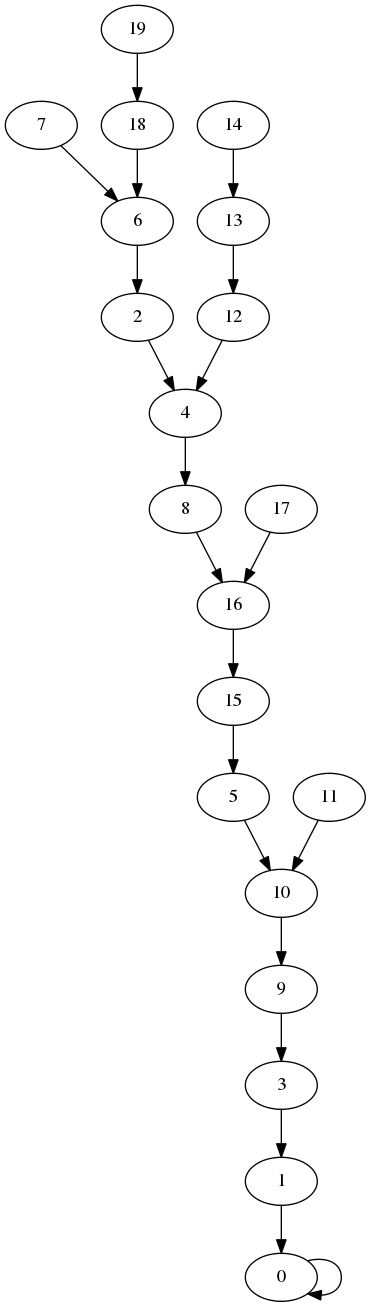
DFS tree
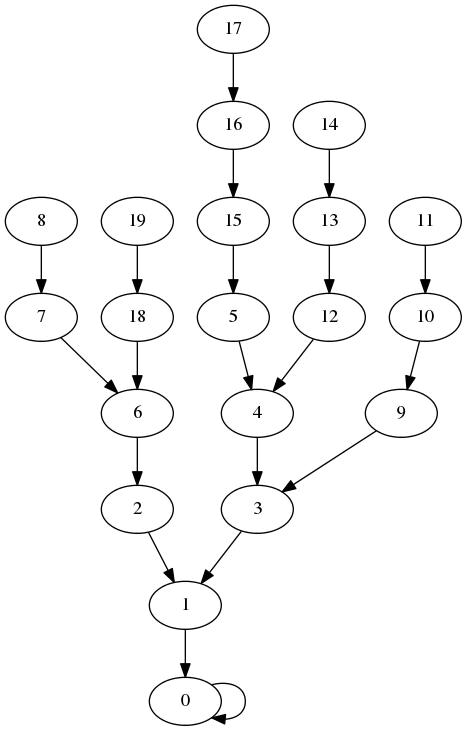
BFS tree
Combined implementation of depth-first and breadth-first search
These are some older implementations of BFS and DFS that demonstrate how both can be written using the same code just by changing the behavior of the core data structure. This also demonstrates how to construct DFS iteratively; for BFS, the preceding implementation is better in every respect.
/* Typical usage:
*
* struct searchInfo *s;
* int n;
*
* s = searchInfoCreate(g);
*
* n = graph_vertices(g);
* for(i = 0; i < n; i++) {
* dfs(s, i);
* }
*
* ... use results in s ...
*
* searchInfoDestroy(s);
*
*/
/* summary information per node for dfs and bfs */
/* this is not intended to be opaque---user can read it */
/* (but should not write it!) */
#define SEARCH_INFO_NULL (-1) /* for empty slots */
struct searchInfo {
Graph graph;
int reached; /* count of reached nodes */
int *preorder; /* list of nodes in order first reached */
int *time; /* time[i] == position of node i in preorder list */
int *parent; /* parent in DFS or BFS forest */
int *depth; /* distance from root */
};
/* allocate and initialize search results structure */
/* you need to do this before passing it to dfs or bfs */
struct searchInfo *searchInfoCreate(Graph g);
/* free searchInfo data---does NOT free graph pointer */
void searchInfoDestroy(struct searchInfo *);
/* perform depth-first search starting at root, updating results */
void dfs(struct searchInfo *results, int root);
/* perform breadth-first search starting at root, updating results */
void bfs(struct searchInfo *results, int root);
examples/graphs/genericSearch.h
#include <stdlib.h>
#include <assert.h>
#include "graph.h"
#include "genericSearch.h"
/* create an array of n ints initialized to SEARCH_INFO_NULL */
static int *
createEmptyArray(int n)
{
int *a;
int i;
a = malloc(sizeof(*a) * n);
assert(a);
for(i = 0; i < n; i++) {
a[i] = SEARCH_INFO_NULL;
}
return a;
}
/* allocate and initialize search results structure */
/* you need to do this before passing it to dfs or bfs */
struct searchInfo *
searchInfoCreate(Graph g)
{
struct searchInfo *s;
int n;
s = malloc(sizeof(*s));
assert(s);
s->graph = g;
s->reached = 0;
n = graphVertexCount(g);
s->preorder = createEmptyArray(n);
s->time = createEmptyArray(n);
s->parent = createEmptyArray(n);
s->depth = createEmptyArray(n);
return s;
}
/* free searchInfo data---does NOT free graph pointer */
void
searchInfoDestroy(struct searchInfo *s)
{
free(s->depth);
free(s->parent);
free(s->time);
free(s->preorder);
free(s);
}
/* used inside search routines */
struct edge {
int u; /* source */
int v; /* sink */
};
/* stack/queue */
struct queue {
struct edge *e;
int bottom;
int top;
};
static void
pushEdge(Graph g, int u, int v, void *data)
{
struct queue *q;
q = data;
assert(q->top < graphEdgeCount(g) + 1);
q->e[q->top].u = u;
q->e[q->top].v = v;
q->top++;
}
/* this rather horrible function implements dfs if useQueue == 0 */
/* and bfs if useQueue == 1 */
static void
genericSearch(struct searchInfo *r, int root, int useQueue)
{
/* queue/stack */
struct queue q;
/* edge we are working on */
struct edge cur;
/* start with empty q */
/* we need one space per edge */
/* plus one for the fake (root, root) edge */
q.e = malloc(sizeof(*q.e) * (graphEdgeCount(r->graph) + 1));
assert(q.e);
q.bottom = q.top = 0;
/* push the root */
pushEdge(r->graph, root, root, &q);
/* while q.e not empty */
while(q.bottom < q.top) {
if(useQueue) {
cur = q.e[q.bottom++];
} else {
cur = q.e[--q.top];
}
/* did we visit sink already? */
if(r->parent[cur.v] != SEARCH_INFO_NULL) continue;
/* no */
assert(r->reached < graphVertexCount(r->graph));
r->parent[cur.v] = cur.u;
r->time[cur.v] = r->reached;
r->preorder[r->reached++] = cur.v;
if(cur.u == cur.v) {
/* we could avoid this if we were certain SEARCH_INFO_NULL */
/* would never be anything but -1 */
r->depth[cur.v] = 0;
} else {
r->depth[cur.v] = r->depth[cur.u] + 1;
}
/* push all outgoing edges */
graphForeach(r->graph, cur.v, pushEdge, &q);
}
free(q.e);
}
void
dfs(struct searchInfo *results, int root)
{
genericSearch(results, root, 0);
}
void
bfs(struct searchInfo *results, int root)
{
genericSearch(results, root, 1);
}
examples/graphs/genericSearch.c
And here is some test code: genericSearchTest.c. You will need to compile genericSearchTest.c together with both genericSearch.c and graph.c to get it to work. This Makefile will do this for you.
Other variations on the basic algorithm
Stacks and queues are not the only options for the bucket in the generic search algorithm. Some other choices are:
- A priority queue keyed by edge weights. If the edges have weights, the generic tree-builder can be used to find a tree containing s with minimum total edge weight. The basic idea is to always pull out the lightest edge. The resulting algorithm runs in O(n + m_log _m) time (since each heap operation takes O(log m) time), and is known as Prim’s algorithm. See Prim’s algorithm for more details.
- A priority queue keyed by path lengths. Here we assume that edges have lengths, and we want to build a shortest-path tree where the length of the path is no longer just the number of edges it contains but the sum of their weights. The basic idea is to keep track of the distance from the root to each node in the tree, and assign each edge a key equal to the sum of the distance to its source and its length. The resulting search algorithm, known as Dijkstra’s algorithm, will give a shortest-path tree if all the edge weights are non-negative. See Dijkstra’s algorithm.
#/media/File:Tallrik_-_Ystad-2018.jpg){kind=link}