Related Books





Books / Introduction to HTML, CSS and JavaScript / Chapter 2
What is HTML?
Markup Languages
The HyperText Markup Language or HTML was derived from Standard Generalized Markup Language (SGML). SGML was designed as a markup language, to allow a writer to markup (or annotate) a document. Markup refers to data included in a document which is different from the document’s content in that it is not included in the presentation of the document for users. Markup languages have been around since at least the 1970’s. Another popular pure markup language still in use is LaTeX, which is used for mathematical, scientific, and engineering documents.
The idea behind a markup language is that a document could be marked-up with tags to tell a program processing the input how to render the text. For example, the following HTML code:
<p>The <i>quick</i> brown fox jumped over the <strong>lazy</strong> dog</p>
would be rendered as:
The quick brown fox jumped over the lazy dog
Markup languages were the precursors of word processing programs that became popular in the 1980’s with the PC revolution. The word processing programs, as they used a What-You-See-Is-What-You-Get (WYSIWYG) interface, which is much easier for a novice computer user to interface with than a markup language. WYSIWYG editors eventually and took over the market for word processing, with a few exceptions such as LaTeX, as mentioned earlier.
SGML was originally a traditional markup language, and hyperlinks between documents were added to create HTML. In the beginning the purpose was to link physics papers together in a web of documents. HTML started with with a browser introduced at CERN in 1990, HTML has expanded far beyond the wildest vision of its creators, but still maintains its markup character.
What is HTML?
HTML is the standard markup language for documents designed to be displayed in web browsers. Web browsers receive HTML documents from a web server and render the documents as web pages. HTML describes the structure of a web page semantically and originally included cues for the appearance of the document.
Like other markup languages, HTML consists of text and tags. Over time, HTML has evolved from
its roots, and is no longer seen simply as a way to format a document.
The HTML language is now used to define the content (or contextual
meaning) of items on a web page, and the tags have evolved to represent
this new role. Most of the original tags specifying how to format text,
such as bolding (<b>), centering (<center>) or italicizing
(<i>), are now considered obsolete and their use is discouraged.
Bolding is now done by the content tag strong <strong>, and
italicizing is done by the content tag emphasis <em>. Formatting is
done based on the content tags using CSS, and interactivity is defined
using embedded JavaScript programming using the <script> tag. HTML has
become much more than a simple markup language, but to understand HTML
it is important to understand its roots as a markup language.
HTML Tags
The tags in HTML are key words defined between a less than sign (<) and
a greater than sign (>), though when using HTML, it is more common to
call them angle brackets. Between the angle brackets are HTML tags and
attributes. For example, the HTML tag to bold text is the word strong,
so to bold text the <strong> tag would be used. The tag represents
actions to be taken by the program that processes the marked-up text.
HTML tags are not case sensitive, so the tags <i> and <I> are
equivalent.
Most tags are applied to a block of text, and apply to the block of the text they enclose. All tags are closed using a slash (/tag), as in the example above where lazy caused the word lazy to be bolded.
The tags shown above are called block tags in that the
first tag (e.g. <i>) specifies where to begin italicizing the text,
and the closing tag (e.g. </i>) specifies where to stop indenting the
text. The text or other information between the two tags is called a
block.
The terms block and container tags are often used interchangeably in HTML. This text will make a distinction between a block and container tag. Semantically it is easier to refer to a block tag as referring to an attribute to apply to all the elements in the block, such as italicizing or bolding the text in the above example. Other tags, such as the div or table tag contain other HTML elements and will be called container tags.
Sometimes a tag, such as a break tag (<br>) or image tag (<img>)
are empty, in the sense that they simply run a command, and do not
apply an attribute to the text. In the case of the <br> tag, the
meaning is to simply skip a line, so it does not affect any text or any
other element. It could be written as <br></br>. However, HTML
provides a short cut for this type of tag. The tag can be closed between
the angle brackets that opened it. The <br> tag can be written as
<br/>. Another example of tag that doesn’t have a closing tag is the <img> tag for displaying images, written as <img />.
As the <br> tag shows, tags can be used to do many things in HTML other
than just markup text. For example, tags can be used to tell the HTML
processor to include a picture. If a picture exists in the same
directory as the web page, the image can be included on the page by
adding the following tag into the HTML for the page:
<img src="dog.jpg" >
This line of code includes the picture from the file dog.jpg in the web page. The tag is the image tag, but the image needs an attribute to indicate where to find the picture. For the image tag the attributed used to find the picture is the src tag.
Attributes are data that fill in details needed to implement the desired behavior for the tag. All tags can have some attributes, and these will be looked at in more detail later.
Standard HTML Tags
There are 4 HTML tags that are considered standard for all web pages.
These tags are the <html>, <head >, <title>, and <body> tags. A
strict HTML5 web page is required to have these 4 tags, and many IDE’s
will automatically insert these 4 tags in a page for you when you start
an HTML page. Since these 4 tags are always recommended for every web
page, I personally keep a template, shown below, that I copy when I
begin all web pages.
<html>
<head>
<title>Please change this to the title of your page </title>
</head>
<body>
</body>
</html>
Program 2 – HTML template
This template code can be represented as a top-down tree, as shown below. In this tree the html tag is used to contain 2 elements, the head and the body. Likewise, the head section contains the title, and as we will see shortly, the head and the body sections will contain many other HTML elements. Thus, we will call these 3 tags container tags. The title only contains a block of text, so it is a block tag.
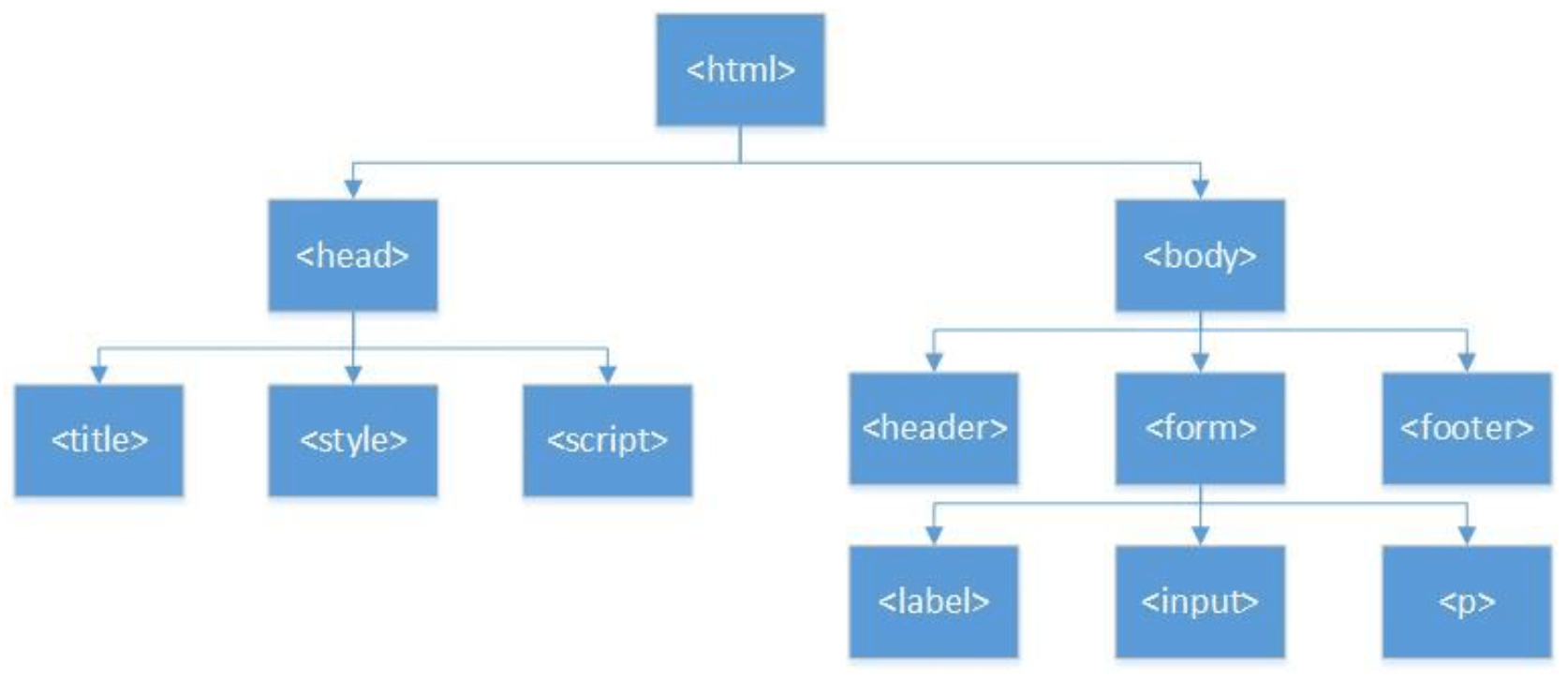
These four tags (html, head, title, and body) are special in that they define the structure of an HTML document and are called Document Structure tags. This will be covered more fully in the next section. But first there are some points to be made about how to structure HTML files.
In the file in Program 2, note that each container tag (html, head, and body) is indented to show the hierarchical structure of the document representing the tree shown in the figure above. This is not required by the HTML processor, as the processor is just looking at strings of instructions and text and ignoring any program format. However, indenting makes it easier for the developer and maintainer of web pages to understand what is going on in the program.
The second thing I always recommend writing html code is to end all
container tags when the beginning tag is entered. This means when
<head> is entered, the </head> is immediately entered. This is the
automatic behavior of many IDEs. The reason to enter a close tag when
opening a container tag is to enforce boundaries on the ideas and
concepts that are being expanded in the container. This does not make
sense to many novices, who seem to see ideas as unstructured information
that starts at the top of the document and just streams to the end.
Novice ideas often appear (to me) to be a jumble of thoughts. They do
not see a purpose in creating boundaries or structure to express of
idea. This is true in all areas of academia, including unreadable papers
and documentation. This is why indenting, and container boundaries are
so important to enforce a structured way of presenting the ideas.
HTML Tag Attributes
HTML attributes are part of HTML tags. They are expressed as name=value pairs within the opening tag. The value may be enclosed in single or double quotes. For example, the <img> tag uses attribute called src to indicate the location of the image:
<img src="/img/cat.png" />
Another very popular attribute is the class attribute. It’s used to specify the CSS class that should be used to style an tag. For example,
<html>
<head>
<style>
.notice_color {
color: red;
}
</style>
</head>
<body>
<p class="notice_color">You have been warned.</p>
</body>
</html>
Here, we assign the CSS class notice_color to <p> tag. It renders like this:
You have been warned.
HTML Headings
HTML has 6 headings defined from <h1> to <h6> with H1 being the largest (or most important) level and H6 the smallest:
<h1>Heading 1</h1>
<h2>Heading 2</h2>
<h3>Heading 3</h3>
<h4>Heading 4</h4>
<h5>Heading 5</h5>
<h6>Heading 6</h6>
This is rendered as:
Heading 1
Heading 2
Heading 3
Heading 4
Heading 5
Heading 6
HTML Comments
HTML comments are enclosed within <!-- and -->. For example,
<!-- This is an HTML comment -->