Related Books





Books / Understanding XML / Chapter 1
Introduction to XML
In this chapter
What is XML?
XML defines a standard way to add markup to documents, which facilitates representation, storage, and exchange of information. A markup language is a mechanism to identify parts of a document and to describe their logical relationships. XML stands for “eXtensible Markup Language” (extensible because it is not a fixed set of markup tags like HTML— HyperText Markup Language). The language is standardized by the World Wide Web Consortium (W3C), and all relevant information is available at: http://www.w3.org/XML/.
Structured information contains both content (words, pictures, etc.) and metadata describing what role that content plays (for example, content in a section heading has a different meaning from content in a footnote, which means something different than content in a figure caption or content in a database table, etc.).
XML is not a single, predefined markup language: it is a metalanguage—language for defining other languages—which lets you design your own markup language. A predefined markup language like HTML defines a specific vocabulary and grammar to describe information, and the user is unable to modify or extend either of these. Conversely, XML, being a meta-language for markup, lets you design a new markup language, with tags and the rules of their nesting that best suite your problem domain.
The perception and nature of the term “document” has changed over the time. In the past, a document was a container of static information and it was often an end result of an application. Recently, the nature of documents changed from passive to active. The documents themselves became “live” applications. Witness the client-side event-handling scripting languages in Web browsers, such as JavaScript. Moreover, great deal of a program’s business logic can be encoded separately, as data, rather than hard-coded as instructions.
Structured Documents and Markup
The word “document” refers not only to traditional documents, like a book or an article, but also to the numerous of other “data collections.” These include vector graphics, e-commerce transactions, mathematical equations, object meta-data, server APIs, and great many other kinds of structured information. Generally, structured document is a document in which individual parts are identified and they are arranged in a certain pattern. Documents having structured information include both the content as well as what the content stands for. Consider these two documents:
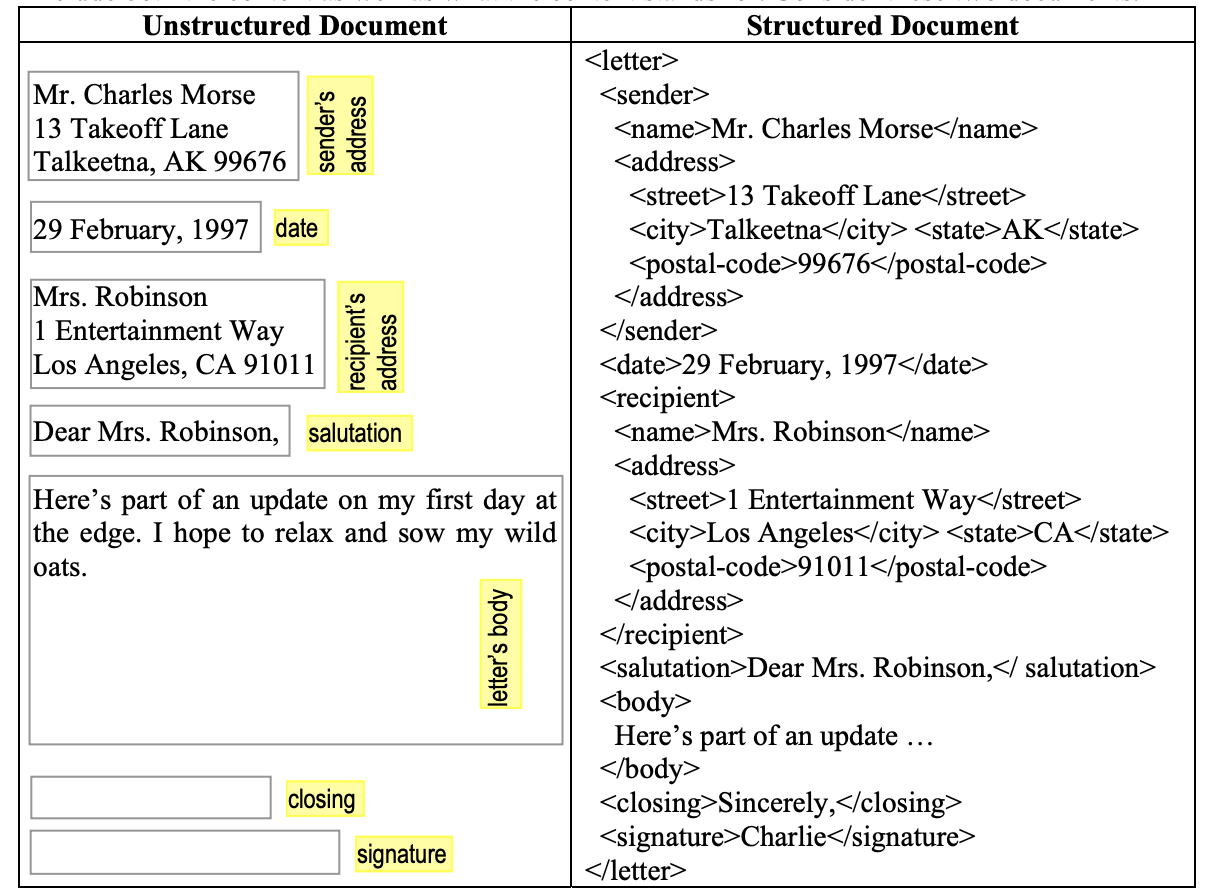
Unstructured Document vs Structured Document in XML.
You probably guessed that the document on the left is a correspondence letter, because you are familiar with human conventions about composing letters. (I highlighted the prominent parts of the letter by gray boxes.) Also, postal addresses adhere to certain templates as well. Even if you never heard of a city called Talkeetna, you can quickly recognize what part of the document appears to represent a valid postal address. But, if you are a computer, not accustomed to human conventions, you would not know what the text contains. On the other hand, the document on the right has clearly identified (marked) parts and their sub-parts. Parts are marked up with tags that indicate the nature of the part they surround. In other words, tags assign meaning/semantics to document parts. Markup is a form of metadata, that is, document’s dictionary capturing definitions of document parts and the relationships among them.
Having documents marked up enables automatic data processing and analysis. Computer can be applied to extract relevant and novel information and present to the user, check official forms whether or not they are properly filled out by users, etc. XML provides a standardized platform to create and exchange structured documents. Moreover, XML provides a platform for specifying new tags and their arrangements, that is, new markup languages.
XML is different from HTML, although there is a superficial similarity. HTML is a concrete and
unique markup language, while XML is a meta-language—a system for creating new markup
languages. In a markup language, such as HTML, both the tag set and the tag semantics are fixed
and only those will be recognized by a Web browser. An <h1> is always a first level heading and
the tag <letter> is meaningless. The W3C, in conjunction with browser vendors and the
WWW community, is constantly working to extend the definition of HTML to allow new tags to
keep pace with changing technology and to bring variations in presentation (stylesheets) to the
Web. However, these changes are always rigidly confined by what the browser vendors have
implemented and by the fact that backward compatibility is vital. And for people who want to
disseminate information widely, features supported only by the latest release of a particular
browser are not useful.
XML specifies neither semantics nor a tag set. The tags and grammar used in the above example are completely made up. This is the power of XML—it allows you to define the content of your data in a variety of ways as long as you conform to the general structure that XML requires. XML is a meta-language for describing markup languages. In other words, XML provides a facility to define tags and the structural relationships between them. Since there is no predefined tag set, there cannot be any preconceived semantics. All of the semantics of XML documents will be defined by the applications that process them.
A document has both a logical and a physical structure. The logical structure allows a document to be divided into named parts and sub-parts, called elements. The physical structure allows components of the document, called entities, to be named and stored separately, sometimes in other data files so that information can be reused and non-textual data (such as images) can be included by reference. For example, each chapter in a book may be represented by an element, containing further elements that describe each paragraph, table and image, but image data and paragraphs that are reused (perhaps from other documents) are entities, stored in separate files.
XML Standard
XML is defined by the W3C in a number of related specifications available here. Some of these include:
-
Extensible Markup Language (XML), current version 1.1 (http://www.w3.org/XML/Core/) – Defines the syntax of XML, i.e., the base XML specification.
-
Namespaces (http://www.w3.org/TR/xml-names11) – XML namespaces provide a simple method for qualifying element and attribute names used in Extensible Markup Language documents by associating them with namespaces identified by URI references.
-
Schema (http://www.w3.org/XML/Schema) – The schema language, which is itself represented in XML, provides a superset of the capabilities found in XML document type definitions (DTDs). DTDs are explained below.
-
XML Pointer Language (XPointer) (http://www.w3.org/TR/xptr/) and XML Linking Language (XLink) (http://www.w3.org/TR/xlink/) – Define a standard way to represent links between resources. In addition to simple links, like HTML’s tag, XML has mechanisms for links between multiple resources and links between read-only resources. XPointer describes how to address a resource, XLink describes how to associate two or more resources.
-
XML Path Language (XPath) (http://www.w3.org/TR/xpath20/) – Xpath is a language for addressing parts of an XML document, designed to be used by both XSLT and XPointer.
-
Extensible Stylesheet Language (XSL) (http://www.w3.org/TR/xsl/) and XSL Transformations (XSLT) (http://www.w3.org/TR/xslt/) – Define the standard stylesheet language for XML.
Unlike programming languages, of which there are many, XML is universally accepted by all vendors. The rest of the chapter gives a brief overview and relevant examples.