Related Books





Books / Understanding XML / Chapter 6
XML Schemas
Background: Schemas: Although there is no universal definition of schema, generally scholars agree that schemas are abstractions or generalizations of our perceptions of the world around us, which is molded by our experience. Functionally, schemas are knowledge structures that serve as heuristics which help us evaluate new information. An integral part of schema is our expectations of people, place, and things. Schemas provide a mechanism for describing the logical structure of information, in the sense of what elements can or should be present and how they can be arranged. Deviant news results in violation of these expectations, resulting in schema incongruence.
XML Schemas: In XML, schemas are used to make a class of documents adhere to a particular interface and thus allow the XML documents to be created in a uniform way. Stated another way, schemas allow a document to communicate meta-information to the parser about its content, or its grammar. Meta-information includes the allowed sequence and arrangement/nesting of tags, attribute values and their types and defaults, the names of external files that may be referenced and whether or not they contain XML, the formats of some external (non-XML) data that may be referenced, and the entities that may be encountered. Therefore, schema defines the document production rules. XML documents conforming to a particular schema are said to be valid documents. Notice that having a schema associated with a given XML document is optional. If there is a schema for a given document, it must appear before the first element in the document.
Here is a simple example to motivate the need for schemas. Previously, I introduced
an XML representation of a correspondence letter and used the tags <letter>, <sender>,
<name>, <address>, <street>, <city>, etc., to mark up the elements of a letter. What if
somebody used the same vocabulary in a somewhat different manner, such as the following?
<?xml version="1.0" encoding="UTF-8"?>
<letter>
<sender>Mr. Charles Morse</sender>
<street>13 Takeoff Lane</street>
<city>Talkeetna, AK 99676</city>
<date>29.02.1997</date>
<recipient>Mrs. Robinson</recipient>
<street>1 Entertainment Way</street>
<city>Los Angeles, CA 91011</city>
<body>
Dear Mrs. Robinson,
Here's part of an update ...
Sincerely,
</body>
<signature>Charlie</signature>
</letter>
We can quickly figure that this document is a letter, although it appears to follow different rules of production than the example. If asked whether the schema above represents a valid letter, you would likely respond: “It probably does.” However, to support automatic validation of a document by a machine, we must precisely specify and enforce the rules and constraints of composition. Machines are not good at handling ambiguity and this is what schemas are about. The purpose of a schema in markup languages is to:
- Allow machine validation of document structure
- Establish a contract (how an XML document will be structured) between multiple parties who are exchanging XML documents
XML Schema Basics
XML Schema provides the vocabulary to state the rules of document production. It is an XML
language for which the vocabulary is defined using itself. That is, the elements and datatypes that are used to construct schemas, such as <schema>, <element>, <sequence>, <string>,
etc., come from the http://www.w3.org/2001/XMLSchema namespace. See Figure 6-1 below.
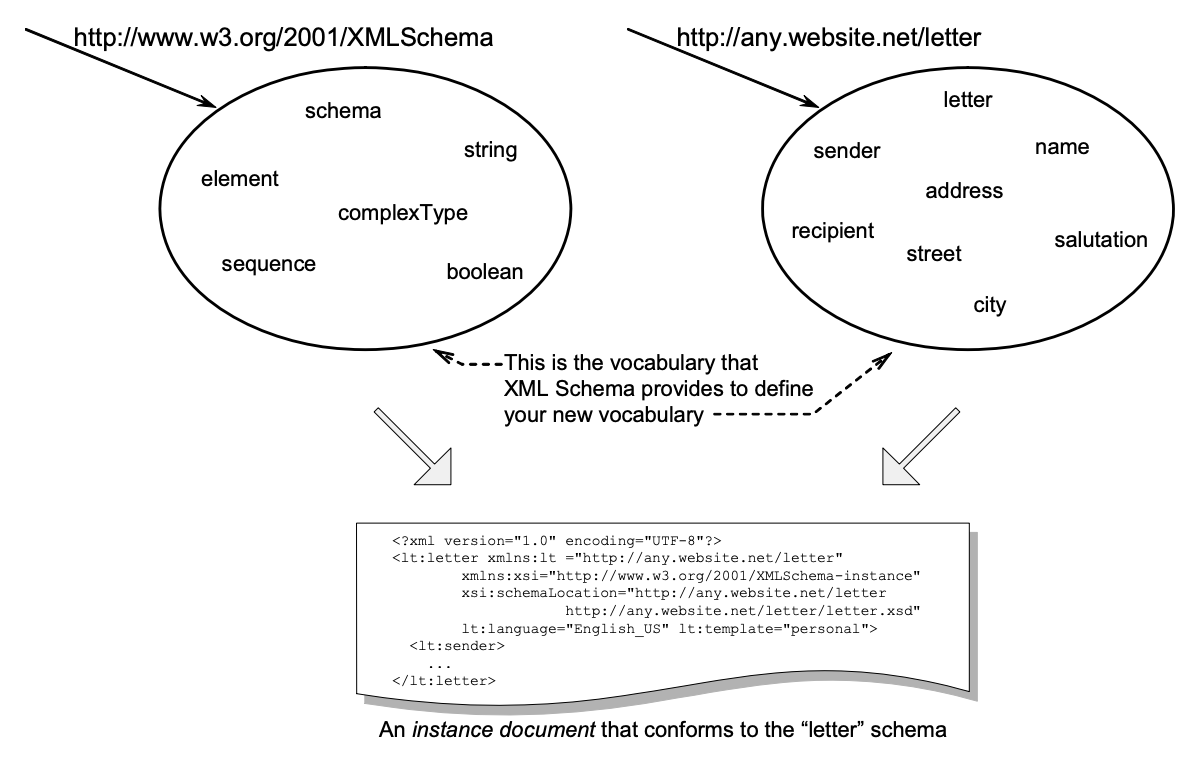
Figure 6-1: Using XML Schema. Step 1: use the Schema vocabulary to define a new XML language (Listing 6-1). Step 2: use both to produce valid XML documents.
Defining XML Schema
The XML Schema namespace is also called the “schema of schemas,” for it defines the elements and attributes used for defining new schemas. The first step involves defining a new language. The following is an example schema for correspondence letters from previous example:
<?xml version="1.0" encoding="UTF-8"?> <!-- Line 1-->
<xsd:schema
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://any.website.net/letter"
xmlns="http://any.website.net/letter"
elementFormDefault="qualified">
<xsd:element name="letter">
<xsd:complexType> <!-- Line 4-->
<xsd:sequence> <!-- Line 5-->
<xsd:element name="sender" type="personAddressType" minOccurs="1" maxOccurs="1"/> <!-- Line 6-->
<xsd:element name="date" type="xsd:date" minOccurs="0"/> <!-- Line 7-->
<xsd:element name="recipient" type="personAddressType"/>
<xsd:element name="salutation" type="xsd:string"/>
<xsd:element name="body" type="xsd:string"/>
<xsd:element name="closing" type="xsd:string"/>
<xsd:element name="signature" type="xsd:string"/>
</xsd:sequence> <!-- Line 13-->
<xsd:attribute name="language" type="xsd:language"/>
<xsd:attribute name="template" type="xsd:string"/>
</xsd:complexType>
</xsd:element> <!-- Line 17-->
<xsd:complexType name="personAddressType"> <!-- Line 18-->
<xsd:sequence>
<xsd:element name="name" type="xsd:string"/>
<xsd:element ref="address"/>
</xsd:sequence>
</xsd:complexType>
<xsd:element name="address">
<xsd:complexType>
<xsd:sequence> <!-- Line 26-->
<xsd:element name="street" type="xsd:string" minOccurs="1" maxOccurs="unbounded"/> <!-- Line 27-->
<xsd:element name="city" type="xsd:string"/>
<xsd:element name="state" type="xsd:string"/>
<xsd:element name="postal-code" type="xsd:string"/>
</xsd:sequence> <!-- Line 31-->
</xsd:complexType>
</xsd:element>
</xsd:schema>
Listing 6-1: XML Schema for correspondence letters from Chapter 2
Here,
- Line 1: This indicates that XML Schemas are XML documents.
- Line 2: Declares the
xsd:namespace. A common convention is to use the prefixxsd:for elements belonging to the schema namespace. Also notice that all XML Schemas have<schema>as the root element—the rest of the document is embedded into this element.targetNamespace: Declares the target namespace ashttp://any.website.net/letter—theelements defined by this schema are to go in the target namespace.xmlns: The default namespace is set tohttp://any.website.net/letter—sameas the target namespace—so the elements of this namespace do not need the namespace qualifier/prefix (within this schema document).elementFormDefault: This directive instructs the instance documents which conform to this schema that any elements used by the instance document which were declared in this schema must be namespace qualified. The default value of elementFormDefault (if not specified) is “unqualified”. The corresponding directive about qualifying the attributes is attributeFormDefault, which can take the same values.
- Lines 3–17: Define the root element
<letter>as a compound datatype (xsd:complexType) comprising several other elements. Some of these elements, such as <salutation>and<body>, contain simple, predefined datatypexsd:string. Others, such as<sender>and <recipient>, contain compound type personAddressType which is defined below in this schema document (lines 18–23). This complex type is also a sequence, which means that all the named elements must appear in the sequence listed. Theletterelement is defined as an anonymous type since it is defined directly within the element definition, without specifying the attribute “name” of the<xsd:complexType>start tag (line 4). This is called inlined element declaration. Conversely, the compound typepersonAddressType, defined as an independent entity in line 18 is a named type, so it can be reused by other elements (see lines 6 and 8). - Line 6: The multiplicity attributes
minOccursandmaxOccursconstrain the number of occurrences of the element. The default value of these attributes equals to 1, so this is redundant and it is omitted for the remaining elements (but, see lines 7 and 27). In general, an element is required to appear in an instance document (defined below) when the value ofminOccursis 1 or more. - Line 7: Element
<date>is of the predefined typexsd:date. Notice that the value of minOccurs is set to 0, which indicates that this element is optional. - Lines 18–23: Define our own personAddressType type as a compound type comprising
person’s name and postal address (as opposed to a business-address-type). Notice that the
postal
<address>element is referred to in line 21 (attribute ref) and it is defined elsewhere in the same document. The personAddressType type is extended as<sender>and<recipient>in lines 6 and 8, respectively. - Lines 24–33: Define the postal
<address>element, referred to in line 21. Of course, this could have been defined directly within the personAddressType datatype, as an anonymous sub-element, in which case it would not be reusable. - Line 27: The multiplicity attribute
maxOccursis set to “unbounded,” to indicate that the street address is allowed to extend over several lines.
Notice that Lines 2
targetNamespaceandxmlnsabove accomplish two different tasks. One is to declare the namespace URI that the letter schema will be associated with (targetNamespace). The other task is to define the prefix for the target namespace that will be used in this document (xmlns). The reader may wonder whether this could have been done in one line. But, in the spirit of the modularity principle, it is always to assign different responsibilities (tasks) to different entities (in this case different lines).
The graphical representation of document structure defined by this schema is shown in figure below.
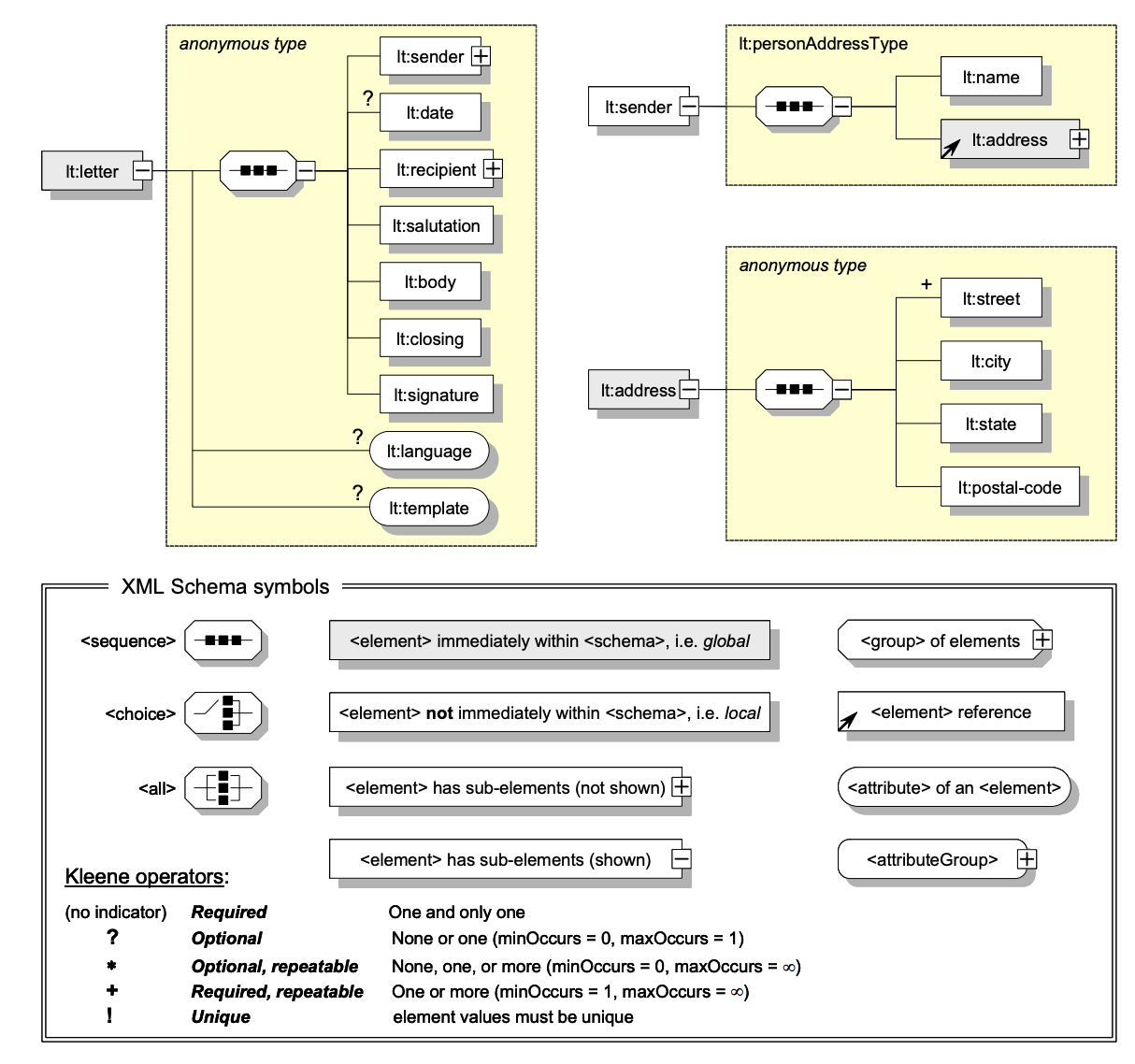
Document structure defined by correspondence letters schema.
Referencing XML Schema
The second step is to use the newly defined schema for production of valid conforms-to instance documents. An instance document is an XML document that conforms to a particular schema. To reference the above schema in letter documents, we do as follows:
<?xml version="1.0" encoding="UTF-8"?>
<!-- Comment: A personal letter marked up in XML. -->
<lt:letter
xmlns:lt ="http://any.website.net/letter"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://any.website.net/letter
http://any.website.net/letter/letter.xsd"
lt:language="en-US" lt:template="personal">
<lt:sender>
<!-- ... -->
<!-- Similar to Complete Example in Chapter 2 -->
</lt:sender>
<!-- ... -->
<!-- Similar to Complete Example in Chapter 2 -->
</lt:letter>
The above listing is said to be valid unlike complete correspondence example in chapter 2 for which we generally only know that it is well-formed. The two documents (letter in chapter 2 and the example above) are the same, except for referencing the letter schema as follows:
- Step 1 (line 3
<lt:letter): Tell a schema-aware XML processor that all of the elements used in this instance document come from thehttp://any.website.net/letternamespace. All the element and attribute names will be prefaced with thelt:prefix. (Notice that we could also use a default namespace declaration and avoid the prefix.) - Step 2 (line 5
xmlns:xsi): Declare another namespace, the XMLSchema-instance namespace, which contains a number of attributes (such asschemaLocation, to be used next) that are part of a schema specification. These attributes can be applied to elements in instance documents to provide additional information to a schema-aware XML processor. Again, a usual convention is to use the namespace prefixxsi:for XMLSchema-instance. - Step 3 (lines
xsi:schemaLocation): With thexsi:schemaLocationattribute, tell the schema-aware XML processor to establish the binding between the current XML document and its schema. The attribute contains a pair of values. The first value is the namespace identifier whose schema’s location is identified by the second value. In our case the namespace identifier ishttp://any.website.net/letterand the location of the schema document is http://any.website.net/letter/letter.xsd. (In this case, it would suffice to only haveletter.xsdas the second value, since the schema document’s URL overlaps with the namespace identifier.) Typically, the second value will be a URL, but specialized applications can use other types of values, such as an identifier in a schema repository or a well-known schema name. If the document used more than one namespace, thexsi:schemaLocationattribute would contain multiple pairs of values (all within a single pair of quotations).
Notice that the schemaLocation attribute is merely a hint. If the parser already knows about
the schema types in that namespace, or has some other means of finding them, it does not have to
go to the location you gave it.
XML Schema defines two aspects of an XML document structure:
- Content model validity, which tests whether the arrangement and embedding of tags is correct. For example, postal address tag must have nested the street, city, and postal-code tags. A country tag is optional.
- Datatype validity, which is the ability to test whether specific units of information are of the correct type and fall within the specified legal values. For example, a postal code is a five-digit number. Data types are the classes of data values, such as string, integer, or date. Values are instances of types.
There are two types of data:
- Simple types are elements that contain data but not attributes or sub-elements. Examples
of simple data values are
integerorstring, which do not have parts. New simple types are defined by deriving them from existing simple types (built-in’s and derived). - Compound types are elements that allow sub-elements and/or attributes. An example is
personAddressTypetype defined in Listing 6-1 (XML Schema). Complex types are defined by listing the elements and/or attributes nested within them.
Models for Structured Content - Content Model
As noted above, schema defines the content model of XML documents—the legal building blocks of an XML document. A content model indicates what a particular element can contain. An element can contain text, other elements, a mixture of text and elements, or nothing at all. Content model defines:
- elements that can appear in a document
- attributes that can appear in a document
- which elements are child elements
- the order of child elements
- the multiplicity of child elements
- whether an element is empty or can include text
- data types for elements and attributes
- default and fixed values for elements and attributes
XML Schema Elements
XML Schema defines a vocabulary on its own, which is used to define other schemas. Here I provide only a brief overview of XML Schema elements that commonly appear in schema documents.
- The
<schema>element defines the root element of every XML Schema. - The
<element>element defines an element. Its parent element can be one of the following:<schema>,<choice>,<all>,<sequence>, and<group>. - The
<group>element is used to define a collection of elements to be used to model compound elements. - The
<attributeGroup>element is used to group a set of attribute declarations so that they can be incorporated as a group into complex type definitions. - The
<annotation>element specifies schema comments that are used to document the schema. This element can contain two elements: the<documentation>element, meant for human consumption, and the<appinfo>element, for machine consumption.
Simple Elements
A simple element is an XML element that can contain only text. It cannot contain any other
elements or attributes. However, the “only text” restriction is ambiguous since the text can be of
many different types. It can be one of the built-in types that are included in the XML Schema
definition, such as boolean, string, date, or it can be a custom type that you can define
yourself as will be seen later. You can also add restrictions (facets) to a data type
in order to limit its content, and you can require the data to match a defined pattern.
Examples of simple elements are <salutation> and <body> elements in Listing 6-1 (XML Schema) above.
Groups of Elements
XML Schema enables collections of elements to be defined and named, so that the elements can be used to build up the content models of complex types. Un-named groups of elements can also be defined, and along with elements in named groups, they can be constrained to appear in the same order (sequence) as they are declared. Alternatively, they can be constrained so that only one of the elements may appear in an instance.
A model group is a constraint in the form of a grammar fragment that applies to lists of element information items, such as plain text or other markup elements. There are three varieties of model group:
- Sequence element
<sequence>(all the named elements must appear in the order listed); - Conjunction element
<all>(all the named elements must appear, although they can occur in any order); - Disjunction element
<choice>(one, and only one, of the elements listed must appear).
XML Schema Datatypes
In XML Schema specification, a datatype is defined by:
- Value space, which is a set of distinct values that a given datatype can assume. For
example, the value space for the integer type are
integernumbers in the range [-4294967296, 4294967295], i.e., signed 32-bit numbers. - Lexical space, which is a set of allowed lexical representations or literals for the datatype.
For example, a
float-type number 0.00125 has alternative representation as1.25E-3. Valid literals for thefloattype also include abbreviations for positive and negative infinity (+/-INF) and Not a Number (NaN). - Facets that characterize properties of the value space, individual values, or lexical items. For example, a datatype is said to have a “numeric” facet if its values are conceptually quantities (in some mathematical number system). Numeric datatypes further can have a “bounded” facet, meaning that an upper and/or lower value is specified. For example, postal codes in the U.S. are bounded to the range [10000, 99999].
XML Schema has a set of built-in or primitive datatypes that are not defined in terms of other
datatypes. We have already seen some of these, such as xsd:string which was used in this chapter. More will be exposed below. Unlike these, derived datatypes are those that are defined in
terms of other datatypes (either primitive types or derived ones).
Simple Types: <simpleType>
These types are atomic in that they can only contain character data and cannot have attributes or element content. Both built-in simple types and their derivations can be used in all element and attribute declarations. Simple-type definitions are used when a new data type needs to be defined, where this new type is a modification of some other existing simpleType-type. A partial list is shown below.
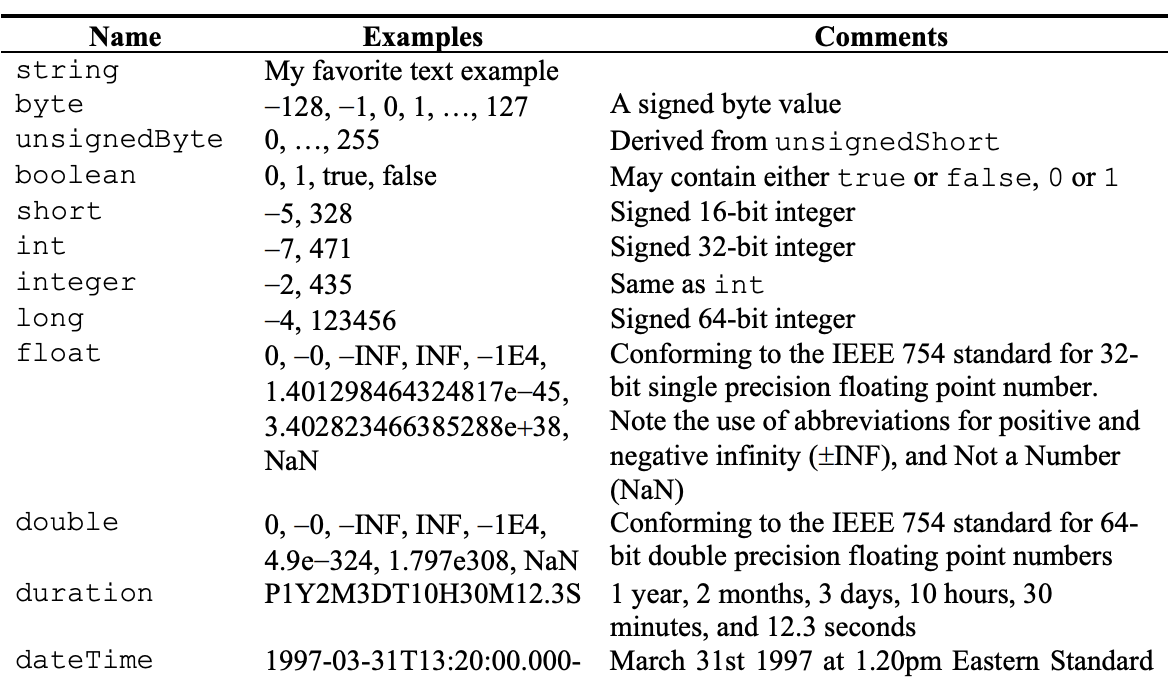
A partial list of primitive datatypes that are built into the XML Schema.
A straightforward use of built-in types is the direct declaration of elements and attributes that
conform to them. For example, in Listing 6-1 above I declared the <signature> element and
template attribute of the <letter> element, both using xsd:string built-in type:
<xsd:element name="signature" type="xsd:string"/>
<xsd:attribute name="template" type="xsd:string"/>
New simple types are defined by deriving them from existing simple types (built-in’s and
derived). In particular, we can derive a new simple type by restricting an existing simple type, in
other words, the legal range of values for the new type are a subset of the existing type’s range of
values. We use the <simpleType> element to define and name the new simple type. We use
the restriction element to indicate the existing (base) type, and to identify the facets that constrain
the range of values. A complete list of facets is provided below.
Facets
We use the “facets” of datatypes to constrain the range of values.
Suppose we wish to create a new type of integer called zipCodeType whose range of values is
between 10000 and 99999 (inclusive). We base our definition on the built-in simple type
integer, whose range of values also includes integers less than 10000 and greater than 99999.
To define zipCodeType, we restrict the range of the integer base type by employing two
facets called minInclusive and maxInclusive (to be introduced below):
<xsd:simpleType name="zipCodeType">
<xsd:restriction base="xsd:integer">
<xsd:minInclusive value="10000"/>
<xsd:maxInclusive value="99999"/>
</xsd:restriction>
</xsd:simpleType>
Example of new type definition by facets of the base type.
The facets identify various characteristics of the types, such as:
length,minLength,maxLength- the exact, minimum and maximum character length of the valuepattern- a regular expression pattern for the value (see more below)enumeration—a list of all possible values (an example given below)whiteSpace—the rules for handling white-space in the valueminExclusive,minInclusive,maxExclusive,maxInclusive—the range of numeric values that are allowed (see example above)totalDigits— the maximum allowed number of decimal digits in numeric valuesfractionDigits— the number of decimal digits after the decimal point
The tables below list the facets that are applicable for built-in types.
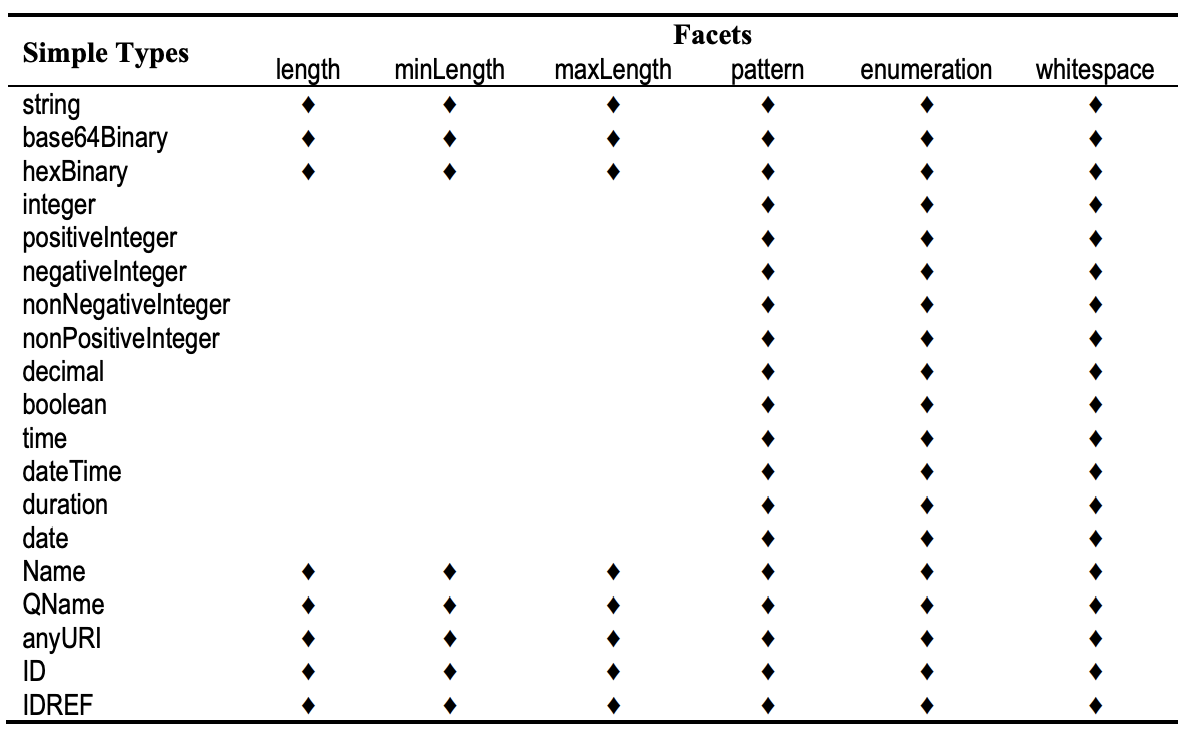
XML Schema facets for built-in simple types. Indicated are the facets that apply to the particular type
The pattern facet is particularly interesting since it allows specifying a
variety of constraints using regular expressions. The following example (Listing 6-10) shows how
to define the datatype for representing IP addresses. This datatype has four quads, each restricted
to have a value between zero and 255, i.e., [0-255].[0-255].[0-255].[0-255]
<xsd:simpleType name="IPaddress">
<xsd:restriction base="xsd:string">
<xsd:pattern
value="(([1-9]?[0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\.){3}
([1-9]?[0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])"/>
</xsd:restriction>
</xsd:simpleType>
Note that in the value attribute above, the regular expression has been split over three lines. This is for readability purposes only; in practice the regular expression would all be on one line.
Compound Types: <complexType>
Compound or complex types can have any kind of combination of element content, character
data, and attributes. The element requires an attribute called name, which is used to refer to the
<complexType> definition. The element then contains the list of sub-elements. You may have
noticed that in the example schema in Listing 6-1, some attributes of the elements from Listing 6-1
were omitted for simplicity sake. For example, <salutation> could have a style attribute,
with the value space defined as {“informal”, “formal”, “business”, “other”}. To
accommodate this, <salutation> should be defined as a complex type, as follows:
<xsd:element name="salutation">
<xsd:complexType>
<xsd:simpleContent>
<xsd:extension base="xsd:string">
<xsd:attribute name="style" use="required">
<xsd:simpleType>
<xsd:restriction base="xsd:string">
<xsd:enumeration value="informal"/>
<xsd:enumeration value="formal"/>
<xsd:enumeration value="business"/>
<xsd:enumeration value="other"/>
</xsd:restriction>
</xsd:simpleType>
</xsd:attribute>
</xsd:extension>
</xsd:simpleContent>
</xsd:complexType>
</xsd:element>
The explanation of the above listing is as follows:
- Line 2: Uses the
<complexType>element to start the definition of a new (anonymous) type. - Line 3: Uses a
<simpleContent>element to indicate that the content model of the new type contains only character data and no elements. - Lines 4–5: Derive the new type by extending the simple
xsd:stringtype. The extension consists of adding a style attribute using attribute declaration. - Line 6: The attribute style is a simpleType derived from
xsd:stringby restriction. - Lines 7–12: The attribute value space is specified using the enumeration facet. The attribute value must be one of the listed salutation styles. Note that the enumeration values specified for a particular type must be unique
The content of a <complexType> is defined as follows and in the figure below:
- Optional
<annotation>(schema comments, which serve as inline documentation) - This must be accompanied by one of the following:
<simpleContent>(which is analogous to the<simpleType>element—used to modify some other “simple” data type, restricting or extending it in some particular way<complexContent>(which is analogous to the<complexType>element— used to create a compound element).
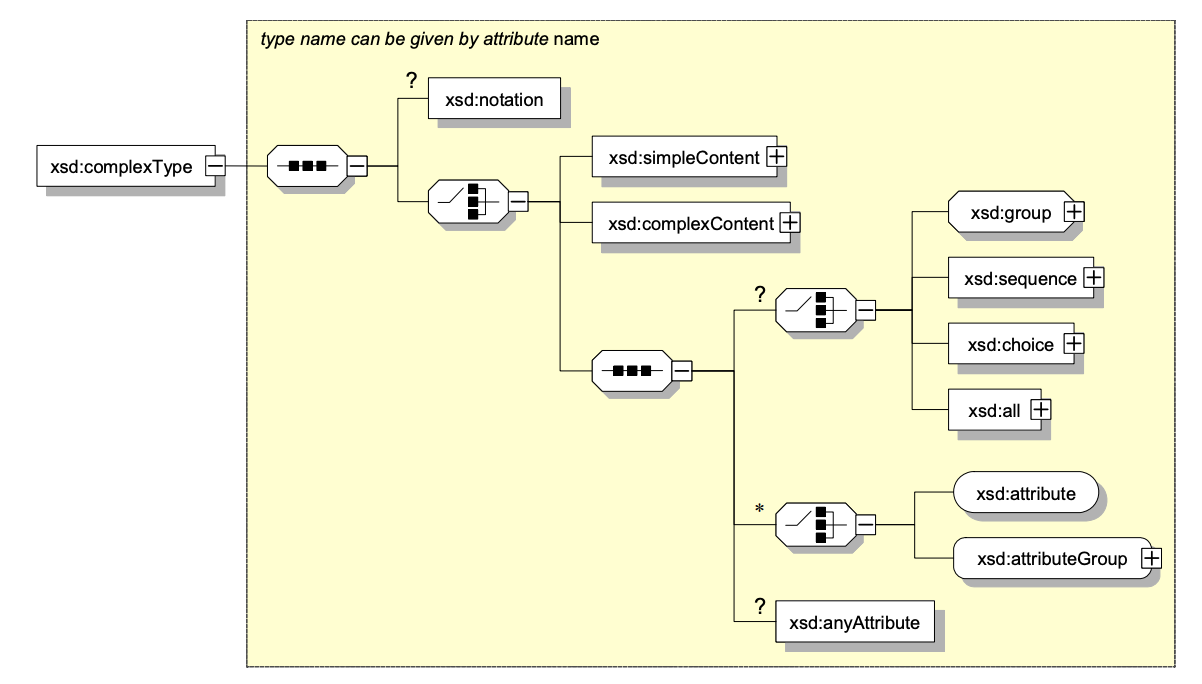
Structure of the XML ComplexType schema element.