Related Books





Books / Understanding XML / Chapter 4
XML Namespaces
Inventing new languages is an arduous task, so it will be beneficial if we can reuse (parts of) an existing XML language (defined by a schema). Also, there are many occasions when an XML document needs to use markups defined in multiple schemas, which may have been developed independently. As a result, it may happen that some tag names may be non-unique. For example, the word “title” is used to signify the name of a book or work of art, a form of nomenclature indicating a person’s status, the right to ownership of property, etc. People easily figure out context, but computers are very poor at absorbing contextual information. To simplify the computer’s task and give a specific meaning to what might otherwise be an ambiguous term, we qualify the term with and additional identifier—a namespace identifier.
An XML namespace is a collection of names, used as element names or attribute names, see examples in the figure below.
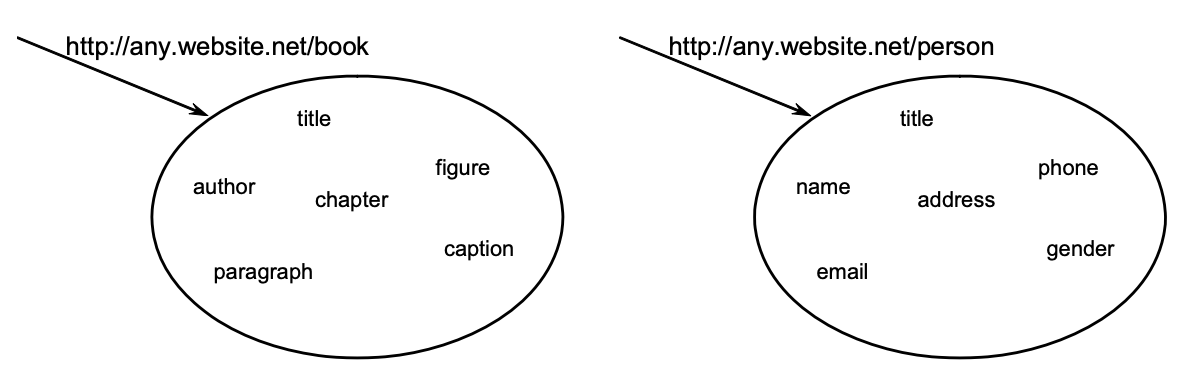
Example XML namespaces providing context to individual names.
The C++ programming language defines namespaces and Java package names are equivalent to namespaces. Using namespaces, you can qualify your elements as members of a particular context, thus eliminating the ambiguity and enabling namespace-aware applications to process your document correctly. In other words:
Qualified name (QName) = Namespace identifier + Local name
A namespace is declared as an attribute of an element. The general form is as follows:

There are two forms of namespace declarations due to the fact that the prefix is optional. The first
form binds a prefix to a given namespace name. The prefix can be any string starting with a letter,
followed by any combination of digits, letters, and punctuation signs (except for the colon “:”
since it is used to separate the mandatory string xmlns from the prefix, which indicates that we
are referring to an XML namespace). The namespace name, which is the attribute value, must be
a valid, unique URI. However, since all that is required from the name is its uniqueness, a URL such as http://any.website.net/schema also serves the purpose. Note that this does
not have to point to anything in particular—it is merely a way to uniquely label a set of names.
The namespace is in effect within the scope of the element for which it is defined as an attribute.
This means that the namespace is effective for all the nested elements, as well. The scoping
properties of XML namespaces are analogous to variable scoping properties in programming
languages, such as C++ or Java. The prefix is used to qualify the tag names, as in the following
example:
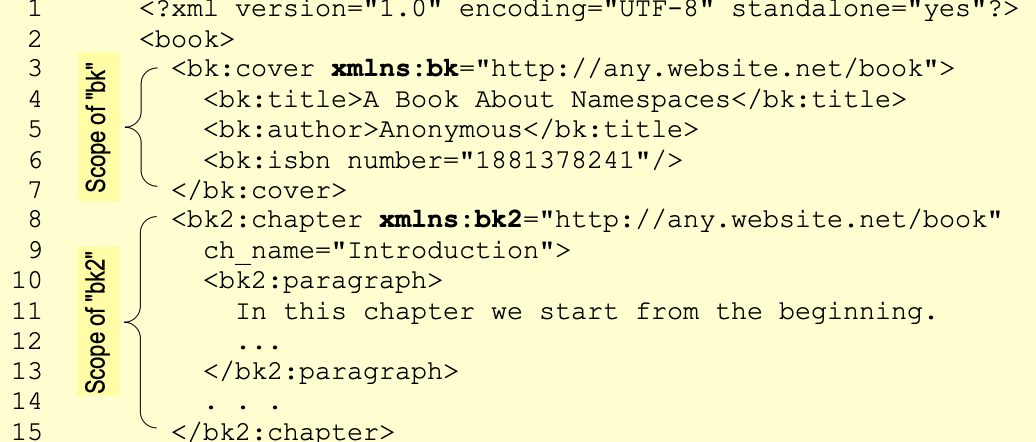
List 4-1 Example of using namespaces in an XML document.
As can be seen, the namespace identifier must be declared only in the outermost element. In our
case, there are two top-level elements: <bk:cover> and <bk:chapter>, and their embedded
elements just inherit the namespace attribute(s). All the elements of the namespace are prefixed
with the appropriate prefix, in our case “bk.” The actual prefix’s name is not important, so in the
above example I define “bk” and “bk2” as prefixes for the same namespace (in different
scopes!). Notice also that an element can have an arbitrary number of namespace attributes, each
defining a different prefix and referring to a different namespace.
In the second form, the prefix is omitted, so the elements of this namespace are not qualified. The namespace attribute is bound to the default namespace. For the above example (Listing 4-1), the second form can be declared as:
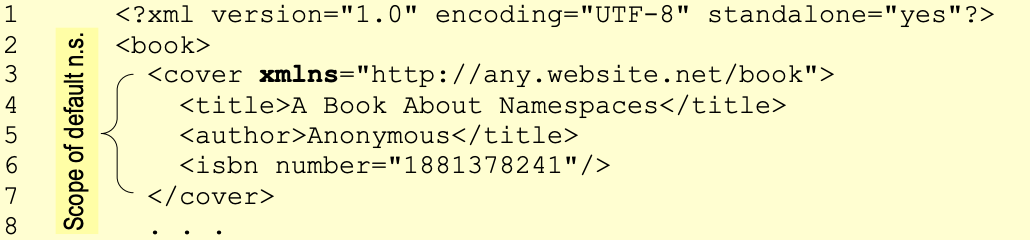
List 4-2 Example of using a default namespace.
Notice that there can be at most one default namespace declared within a given scope. In Listing 4-2, we can define another default namespace in the same document, but its scope must not overlap with that of the first one.