It was April. Year was probably was 2010. The cold, snowy winter was finally coming to an end and the spring was almost in the air. I was preparing for my final exams. The review lectures were going on for the RDBMS course that I was enrolled in at my university.

Around the same time, I had started hearing and reading about the shiny, new technology that was going to change the way we use databases. The NoSQL movement was gaining momentum. I was reading blogs about how MongoDB is big time outperforming ancient, non web scale relational databases.
After the lecture, I asked my professor:
Me: So, between RDBMS and NoSQL databases, which one do you think is the best?
Professor: Well, it depends.
Me: Depends on what?
Professor: Depends on what you are trying to achieve. Both have their pros and cons. You pick the right tool for the job.
Me: But MySQL can’t really scale.
Professor: How do you think we got this far? Send me an email and I’ll send you some papers and practical uses in the industry.
SQL was hard for my brain, especially the joins. I loved NoSQL. Simple key->value model without any joins! RDBMS systems that were designed in 1960’s were simply not enough to keep up with modern demands. I had lost all interest in RDBMS and predicted they’ll just fade off in the next few years.
It’s 2012. We’re redesigning my employer’s flagship product. The first version was a monolith that used the boring MySQL. Spending too much time reading blogs and Hacker News comments section, we convinced ourselves that we need to go big and modern:
- Break monolith into service-oriented architecture, aka, the SOA.
- Replace MySQL with Cassandra (MySQL to Redis to Cassandra)
And we built it.
There was nothing wrong with the new system… except one major flaw. It was too complex for a small startup team to maintain. We had built a Formula One race car, that makes frequent pit-stops and requires very specialized maintenance, when we needed a Toyota Corolla that goes on for years and years on just the oil change.
Fast forward to 2017. It feels like almost all software developers I interview these days, have hands-on experience with microservices architecture and many have even actually used it in production.
A grey San Francisco afternoon. I’m conducting an on-site interview. Masters degree and 3 years of experience at a startup that looked like it didn’t make it. I asked him to tell me about the system he built.
Guy: We built the system using the microservices architecture. We had lots of small services which made our life really easy…
Me: Tell me more about it
Guy: Data was written to the BI system through a Kafka cluster. Hadoop and MapReduce system was built to process data for analytics. The system was super scalable.
I pressed him to tell me drawbacks of microservices architecture and problems it introduces. The guy tried to hand-wave his way through and was convinced, just like I was in 2010 about NoSQL databases, that there are absolutely no issues with microservices architecture.
I’m not saying microservices architecture is bad. It has its pros and cons. Organizations who have very complex systems that justify the operational burden, the overhead, it introduces. Martin Fowler, who coined the term microservices, warns us of the “microservices premium”:
The fulcrum of whether or not to use microservices is the complexity of the system you’re contemplating. The microservices approach is all about handling a complex system, but in order to do so the approach introduces its own set of complexities. When you use microservices you have to work on automated deployment, monitoring, dealing with failure, eventual consistency, and other factors that a distributed system introduces. There are well-known ways to cope with all this, but it’s extra effort, and nobody I know in software development seems to have acres of free time.
So my primary guideline would be don’t even consider microservices unless you have a system that’s too complex to manage as a monolith. The majority of software systems should be built as a single monolithic application. Do pay attention to good modularity within that monolith, but don’t try to separate it into separate services.
Netflix is a great example. Their system grew too large and too complex to justify switching to microservices.
In almost all cases, you can’t go wrong by building a monolith first. You break your architecture into services-oriented or… microservices when the benefits outweigh the complexity.
The guy also mentioned Kafka. System that handles 2 million writes a second at LinkedIn:
Me: How much data do you stream to Kafka roughly?
Guy: We could stream gigabytes of logs…
Me: How much data are you streaming right now?
Guy: Not a whole lot right now because we only have 3 customers. But the system could scale up to support millions and millions of users. Also, with both Kafka and Hadoop clusters, we get fool-proof fault-tolerance
Me: How big is the team and company?
Guy: Overall, I guess there were (less than 10) people in the company. Engineering was about 5.
At this point, I was tempted to ask if he had ever heard of YAGNI:
Yagni … stands for “You Aren’t Gonna Need It”. It is a mantra from Extreme Programming … It’s a statement that some capability we presume our software needs in the future should not be built now because “you aren’t gonna need it”.
People sometimes have honest intentions and they don’t introduce new tools, libraries, frameworks, just for the sake of enhancing their resumes. Sometimes they simply speculate enormous growth and try to do everything up front to not have to do this work later.
The common reason why people build presumptive features is because they think it will be cheaper to build it now rather than build it later. But that cost comparison has to be made at least against the cost of delay, preferably factoring in the probability that you’re building an unnecessary feature, for which your odds are at least ⅔.
People know complexity is bad. No one likes to see bugs filed on JIRA or get PagerDuty alerts at 3 a.m. that something is wrong with Cassandra cluster. But why do software developers still do it? Why do they choose to build complex systems without proper investigation?
Are there other reasons for building complex features besides preparing for a hypothetical future?
I’m sure majority of you are familiar with the term cargo cult software development. Teams who slavishly and blindly follow techniques of large companies they idolize like Google, Apple or Amazon, in the hopes that they’ll achieve similar success by emulating their idols.
Just like the South Sea natives who built primitive runways, prayed and performed rituals in the hopes that planes would come in and bring cargo, the food and supplies. Richard Feynman warned graduates at the California Institute of Technology to not fall victim to the cargo cult thinking:
In the South Seas there is a cargo cult of people. During the war they saw airplanes land with lots of good materials, and they want the same thing to happen now. So they’ve arranged to make things like runways, to put fires along the sides of the runways, to make a wooden hut for a man to sit in, with two wooden pieces on his head like headphones and bars of bamboo sticking out like antennas — he’s the controller — and they wait for the airplanes to land. They’re doing everything right. The form is perfect. It looks exactly the way it looked before. But it doesn’t work. No airplanes landed.

It reminded me of the time when we took a perfectly good monolith and created service-oriented architecture (SOA). It didn’t work. The planes didn’t land.
Whatever the reasons:
- not wanting to be left out: the new Javascript framework from this week will be the next hottest thing.
- enhancing resume with buzzwords: Monolith won’t impress recruiters / interviewers.
- imitating heroes: Facebook does it, Google does it, Twitter does it.
- technology that could keep up with the projected 5000% YoY company growth: YAGNI.
- latest tools to convince people that you’re a proper SF bay area tech company.
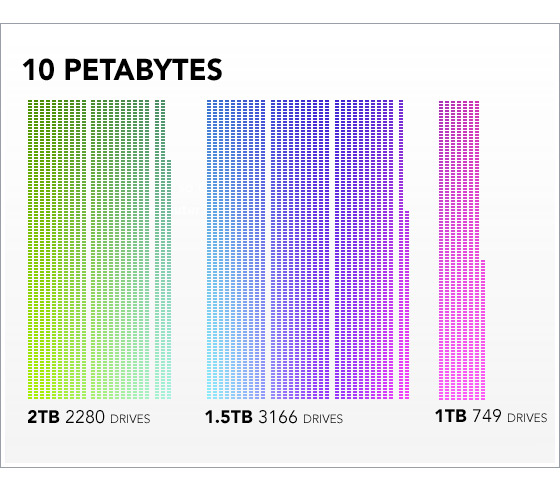
Cargo-cult engineering just doesn’t work. You are not Google. What works for them will most likely not work for your much, much smaller company. Google actually needed MapReduce because they wanted to regenerate indexes for the entire World Wide Web, or something like that. They needed fault tolerance from thousands of commodity servers. They had 20 petabytes of data to process.
20 petabytes is just enormous. In terms of the number of disk drives, here’s what half of that, 10 petabytes, would look like:
To avoid falling in the cargo-cult trap, I have learned to do the following:
- Focus on the problem first, not the solution. Don’t pick any tool until you have fully understood what you are trying to achieve or solve. Don’t give up solving the actual problem and make it all about learning and using the shiny new tech.
- Keep it simple. It’s an over-used term, but software developers still just don’t get it. Keep. It. Simple.
- If you are leaning towards something that Twitter or Google uses, do your homework and understand the real reasons why they picked that technology.
- When thinking of growth, understand that the chances of your startup growing to be the size of Facebook are slim to none. Even if your odds are huge, is it really worth all this effort to set-up a ‘world-class foundation’ now vs doing it later?
- Weigh operational burden and complexity. Do you really need multi-region replication for fault-tolerance in return of making your DevOps life 2x more difficult?
- Be selfish. Do you want to be woken up in the middle of night because something, somewhere stopped working? There is nothing wrong with learning the new JavaScript framework from last week. Create a new project and publish it on GitHub. Don’t build production systems just because you like it.
- Think about people who’d have to live with your mess. Think about your legacy. Do people remember you as the guy who built rock-solid systems or someone who left a crazy mess behind?
- Share your ideas with experts and veterans and let them criticize. Identify people in other teams who you respect and who’d disagree freely.
- Don’t jump to conclusions on the results of quick experiments. HelloWorld prototypes of anything is easy. Real-life is very different from HelloWorld.
We discussed YAGNI in this post, but it is generally applied in the context of writing software, design patterns, frameworks, ORMs, etc. Things that are in control of one person.
YAGNI is coding what you need, as you need, refactoring your way through.
Back to the guy I interviewed. It’s highly unlikely, even for a small startup, that a software developer in the trenches was allowed to pick Hadoop, Kafka and microservices architecture. Cargo cult practices usually start from someone higher up the ranks. A tech leader who may be a very smart engineer, but very bad at making rational decisions. Someone who probably spends way too much time reading blogs and tries very hard keep up with the Amazon or Google way of building software.
2017 is almost over. NoSQL has matured. MongoDB is on its way out. DynamoDB is actually a very solid product and is maturing really well. RDBMS systems didn’t die. One can argue they are actually doing pretty good. StackOverflow is powered by just 4 Microsoft SQL Servers. Uber runs on MySQL.
You may have great reasons to use MapReduce or SOA. What matters is how you arrive at your decision. Whether by careful, sane thought or by jumping on the bandwagon and cargo-cult’ing.
As my professor said: “Pick the right tool for the job.” I’ll also add: don’t build Formula One cars when you need a Corolla.
Comments (22)
T W M G
“People sometimes have honest intentions and they don’t introduce new tools, libraries, frameworks, just for the sake of enhancing their resumes.”
Completely disagree. People pick what is good for them and their career. Not what is good for the business.
LeftZero
“Post hoc ergo propter hoc” https://en.wikipedia.org/wi…
Spike McLarty
“People pick what is good for them and their career. Not what is good for the business.”
Completely disagree.
(Professionalism, responsibility, sample size, confirmation bias, blah blah blah) TL;DW.
Jalmari Ikävalko
Eh, I’m personally quite convinced that SOA-style approaches are infact more maintanable for small teams. Okay, it’s pretty stupid if you start setting up fully tuned and tested workload balancers, spread the computational load via Hadoop, pass all the messages through Kafka, and make your services into like 2-3 functions each, all requiring complex discovery systems and whatnot.
But in principle, architehturing your software to fully independent sections that communicate with each other through a pre-defined API has a lot of advantages for even a small team. New people can dive and mess around with a single service right away. The system has a tendency to document itself fairly well. One or the other service going down is not (necessarily) the end of the world. If, from some reason, you really need to rewrite one or two of them, you can in a reasonable time.
Now there’s zero need to do this as “real microservices”; you can run it all on the same computer, make individual services relatively large (if it’s a small web backend, might be just one service), etc. The overhead doesn’t need to be big.
Kevin
I am of a very similar sentiment. Too often I have seen the monolith becoming an unmaintainable mess even after the company has well succeeded. Sometimes it makes sense to express decoupling on a hardware level. It emphasizes boundaries. The examples provided in this post are not great anti examples. Yes kafka etc certainly is not trivial. But from what I can see:
Just like SOA has been used and abused, likewise YAGNI. Hype driven development is certainly not a good thing; but to claim that a monolith is the best starting point always is unbalanced as well. You need to reason your architecture on the basis of first principles. Identifying bottlenecks and addressing them early on is also an exercise in limiting feature driven development and to come to a bare bones MVP. Once that foundation has been set; now you can build on top of that. This is basically the YAGNI of product development. Early on the vision of the product tends to be fantastical with a whole bunch of features from A to Z whereas you have not yet done market validation. Why do we engineers have to always succumb to such an unreasonable vision by adopting a monolith in which we can construct a rainbow mud ball? Part of the work of an engineer is to say no and ensure that the architecture can grow naturally. If every new feature makes it that your architecture has to be contradicted and retrofitted, then this is clearly a sign that there is a lack of balance and foresight. When you properly zoom into the MVP and reason your architecture on the basis of first principles then what is the big deal of emphasizing your boundaries on a hardware level?
DomesticMouse
The reason micro-services work at large companies is that the micro-service forces the development team to own their code from requirements gathering to production support, along with monitoring usage metrics and making sure customers of the service are happy.
The follow on from this is that if the team in question is just a handful of people that own the whole codebase, end to end, then the correct number of micro-services for the team in question is probably 1. Once the team is large enough to split, turn it into a two micro-services app.
Yoni Goldberg
Did you mean at the beginign to write:
“But SQL can’t scale”
?
You wrote mySQL, just trying to ensure that I got the ancedote right :)
Umer Mansoor
Ha! I was referring to relational databases :)
Umer Mansoor
Yes, SQL or RDBMS would also be fine :)
MySQL is what we were using for the course. Oracle (commercial) was out of the question. If I was going to use SQL or RDBMS, it’d have to be MySQL or Postgres.
Umer Mansoor
SOA is the absolutely the right choice, IF it delivers real business value. Amazon switched to SOA after they were already large enough and their organization and team communication structure was modelled in a way that made SOA the right choice.
1. Clearly defined contracts. Even small things like response times. (I witnessed a failure where some service, in a spiderweb of dependencies, failed because an engineer made a ‘tiny’ change that doubled the response time. Took many days to debug and identify the issue. There were no contracts)
2. Clearly define service boundaries (based on the team structure)
2. Independent teams of smart engineers who own the service end to end including design, development, deployment and monitoring.
3. A good infrastructure which makes it all possible. (Friends at Amazon told me that their first task was to setup and integrate with the CI/CD pipeline.)
Here’s an example where SOA was done wrong. A small team of say 7 developers. Working on a monolith. Divides monolith into 4-5 services just because SOA ‘is the best’. Service boundaries are poorly defined. No one owns any service: engineers work across all of them. Poor metrics to identify issues. This team was running SOA, services in their own clusters, dealing with dependencies, or no benefit at all.
More than system’s architecture, SOA is a way of structuring different teams, finding issues in production (hard in monolith) and holding teams accountable.
Kevin
Structuring teams is a logical consequence of SOA It is not the reason to do SOA.
Umer Mansoor
Sometimes they do.
“Hire good people” It’s very hard and sometimes you have to wait for months.
Identify people who are ‘taking a break’ to learn new technologies on the job before they apply to Amazon or Google. Or senior developers who constantly worry about becoming ‘obsolete’ and as a result, try to expand their knowledge by integrating new fads they read up on Hacker News, O’Reilly, ThoughtWorks, etc. into production system.
Good software developers take pride in their work and they do care about their legacy, may be even reputation. I’ve seen good developers being super embarrassed when bugs are found.
I also understand there has to be balancing act and it cannot be black and white. I won’t expect to retain ‘A class’ developer to work on PHP and Microsoft Access. Or continue working on obsolete telecommunications technologies that no one is hiring for. They won’t stay or in worst case, they’d stay but mentally check out. Either convince them and align with their goals or make wise concessions.
Jalmari Ikävalko
And my argument is that even in a team of only a few people, splitting a project along a few key services/individual processes/whatever can still be the correct choice over a single monolith.
We tend to already work in projects that are split along multiple ‘natural’ boundaries. Let’s say, our product is gathering and visualizing some sensor data.
We might already have;
* Web backend that handles our users, data storage and processing and server-side rendering (if we have any)
* Web frontend for retrieving the data and managing our clients and seeing which data-gathering devices are online
* Actual database (even though we didn’t do it ourselves, it’s still its own key service with its own clearly defined API)
* The software that runs on the hardware doing the data gathering.
So now we’re developing 3 subproducts (or 4 if we count the database design and maintenance and all that as the 4th product).
Now if we decided to build the web backend as such that say, user management is a service and data handling is a service, we can start talking about having somekind of a SOA approach. In this particular case, I do not foresee the overhead getting particularly large, but I can still see possible advantages even for a small team. You get some independence and can update the services one by one. Getting familiar with the other is really fast even with limited documentation. You enforce clear API definitions, which are always important be it a monolith or SOA. If it turns out that one or the other service kinda sucks/whatever, rewriting is easier. If you have a lot of client-specific requirements, you can bundle them as services rather than pollute the monolith’s space with them.
I think services tend to have maintanability and expandability advantages while the overhead is manageable as long as one doesn’t start making like loadbalancers or broadcasting and discovery systems or stuff like that before they are actually due.
p7rdev
All the benefits you mentioned sound like you need libraries or modules instead of SOA approach. It has communication overhead and rather than calling functions you deal with HTTP clients, JSON and timeouts. A1,A2,A3 talks to B1,B2,B3. You make a non-backwards compatible change in service B. You run into many issues the minute you update B’s cluster one by one.
If you’re 5 developers sitting around a whiteboard designing SOA and then decide how you’re going to organize yourselves for the 4 services you created, it sounds like a ridiculous application of “reverse Conway’s law”. If you have teams of 30+ devs broken into teams of 5-6, that’s different.
Adam D.
Microservices definition leaves a lot to be desired. It ties the definition to infrastructure which is not correct. It’s about managing coupling and cohesion. I can have microservices hosted in the same thread in one process, on one machine. Can you with an O(c) effort scale your solution up by replacing infrastructure as your user base grows? That’s microservices. We’re being misguided by tooling and infrastructure peddlers.
Jalmari Ikävalko
In a project I mentioned above, there’s no real way to get to fewer than 3-4 separate subproducts. You need to run something on the client hardware, you need to run something on your servers, need to run something in the browser and need to also store the data. How’s the overhead suddenly blown out the water if you decide to further split one of those subproducts into 2-4 individual pieces/services?
When speaking specifically of web backends - IMO even a single developer can as well build their web backend out of separately ran projects and it doesn’t need to be a large overhead development-wise. When you’ve a basic CI environment set up, it shouldn’t make a huge difference whether you’re setting 2 or 3 or 4 projects up with it.
Regarding the issues you mention; if you run it all on same computer, you wont have a problem with timeouts. JSON doesn’t matter if that’s the native format you’re already dealing lots with. And since you’re anyway making a web backend, it’s not like you aren’t knee deep in HTTP anyway. Non-backwards compatible changes are an equal issue with libraries and modules all the same.
patgannon
Generally agreed, but hiring in the valley is tough, and top notch developers generally don’t want to build corollas
Umer Mansoor
I agree with you. New tools and technologies make developers happy. It’s a fact.
Sometimes choosing a new exciting framework over boring old one, does make sense and it’s the right choice. On the other extreme, I have seen some managers/leads just blanket ban anything new and mandate that only technologies X,Y,Z must be used, no exceptions. That’s also wrong.
You’ll have to make compromises if you wish to retain smart people and keep them engaged.
Sure, you don’t want to take risks with the main application. What about less critical applications, internal scripts, libraries? I’m sure managers/leads can find plenty of less-risky opportunities to have their development team experience new technology.
SelrahcD
We can do great stuff, good code and solve problem with PHP too ;)
ihe
Thank you. Should be required reading for every CTO/CIO and IT project manager.
T Lanza
Spot on article. If you’re a pre-monetization startup and worrying about stupid things like tech debt, you should get your head checked.
jj_m
my startup hired a lead engineer from a big company as VP of engineering (entertainment app that was gaining traction) his first big project? code clean up because he believed the error codes were not descriptive enough. result? 4 months down the drain into something that no one ever used. thankfully, the co founders realized their mistake and fired the guy