Docker is awesome. It enables software developers to package, ship and run their applications anywhere without having to worry about setup or dependencies. Combined with Kubernetes, it becomes even more powerful for streamlining cluster deployments and management. I digress. Back to Docker. Docker is loved by software developers and its adoption rate has been remarkable.
In this post, we’ll look at how Docker works under the hood. Docker uses a technology called “Containerization” to do its magic and that’s what we are going to explore next.
Why Do We Need Containers?
Let’s say you want to run a software Foo on your computer. Foo requires Node.js version 10 (assume Foo is incompatible with newer Node.js versions), so you install Node 10 on your machine. Later, you want to run another software, Bar, which requires Node.js version 15.
This has created a problem. (Assume we can’t use nvm to switch between Node versions easily.)
One way we could solve this problem is by using Virtual Machines or VMs to create isolated environments for running Foo and Bar. You can create one VM with Foo and Node 10 and another with Bar and Node 15. Voila, we are back in business.
However, there’s an issue with this approach: it’s very inefficient. Each VM requires its own operating system. We are now running two separate guest operating systems on our computer just to run two different processes.
What if there was a way to run Foo and Bar and your machine without running two extra operating systems?
Let’s review the interaction between processes and operating system. Whenever a process wants to do anything, it asks the operating system. Processes like Foo and Bar would ask the OS questions like, “which Node version do you have installed?” or “how much memory is available to me?” or “what other processes are running?”
What if we could intercept and control the communication between processes and operating systems and send customized responses to processes to control their behavior? For example, when Foo and Bar ask “what Node version do you have installed”, we tell Foo that we have Node v10 and send its executable location to Foo. When Bar asks the same question, we respond with Node v16. In other words, what if we create a virtual OS for Foo and Bar?
This is exactly what containers do. They allow us to run different processes, Foo and Bar, on the same OS. A container runtime intercepts these questions from processes and gives a customized response. It will tell Foo that Node 10 is installed, and Bar will receive a response that the machine only has Node 15.
By strategically modifying responses to Foo and Bar, we have essentially isolated their environments without running separate operating systems. This strategy is called “containerization”.
Docker is a set of tools and a widely popular container runtime. It’s a complete platform for building, testing, deploying and publishing containerized applications. I say platform because Docker is a set of tools for managing all-things related to containers.
Now that we understand the use case for containers and what they are, let’s take a more in-depth look and how they actually work to achieve isolation.
What are Containers?
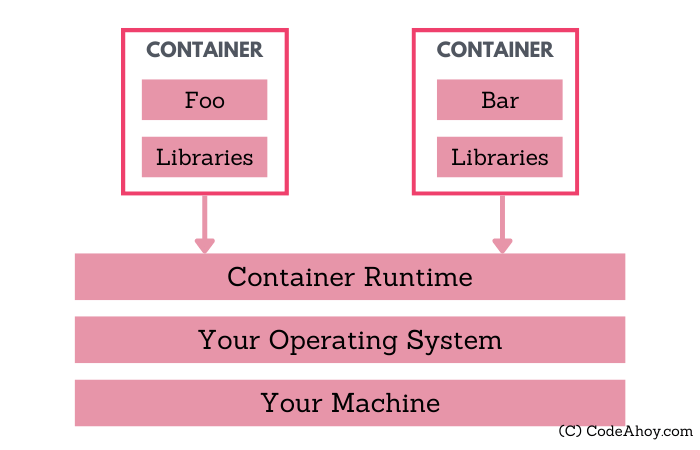
Containers provide a way to install and run your applications in isolated environments on a machine. Applications running inside a container are limited to resources (CPU, memory, disk, process space, users, networking, volumes) allocated for that container. Their visibility is limited to container’s resources and doesn’t conflict with other containers. You can think of containers as isolated sandboxes on a single machine for applications to run in.
As we have discussed, this concept is very similar to virtual machines. The key differentiator is that containers use a light-weight technique to achieve resource isolation. The technique used by containers exploits features of the underlying Linux kernel as opposed to hypervisor based approach taken by virtual machines. In other words, containers call Linux commands to allocate and isolate a set of resources and then runs your application in this space. Let’s take a quick look at two such features:
1. namespaces
I’m over simplifying but Linux namespaces basically allow users to isolate resources like CPU, between independent processes. A process’ access and visibility are limited to its namespace. So users can run processes in one namespace without ever having to worry about conflicting with processes running inside another namespace. Processes can even have the same PID on the same machine within different containers. Likewise, applications in two different containers can use port same ports (e.g. port 80).
2. cgroups
croups allow putting limits and constraints on available resources. For example, you can create a namespace and limit available memory for processes inside it to 1 GB on a machine that has say 16 GB of memory available.
By now, you’ve probably guessed how Docker works. Behind the scenes, when you ask Docker to run a container, it sets up a resource isolated environment on your machine. Then it copies over your packaged application and associated files to the filesystem inside the namespace. At this point, the environment setup is complete. Docker then executes the command that you specified and hands over the control.
In short, Docker orchestrates by setting up containers using Linux’s namespace and cgroups (and few other) commands, copying your application files to disk allocated for the container and then running the startup command. It also comes with a bunch of other tools for managing containers like the ability to list running containers, stopping containers, publishing container images, and many others.
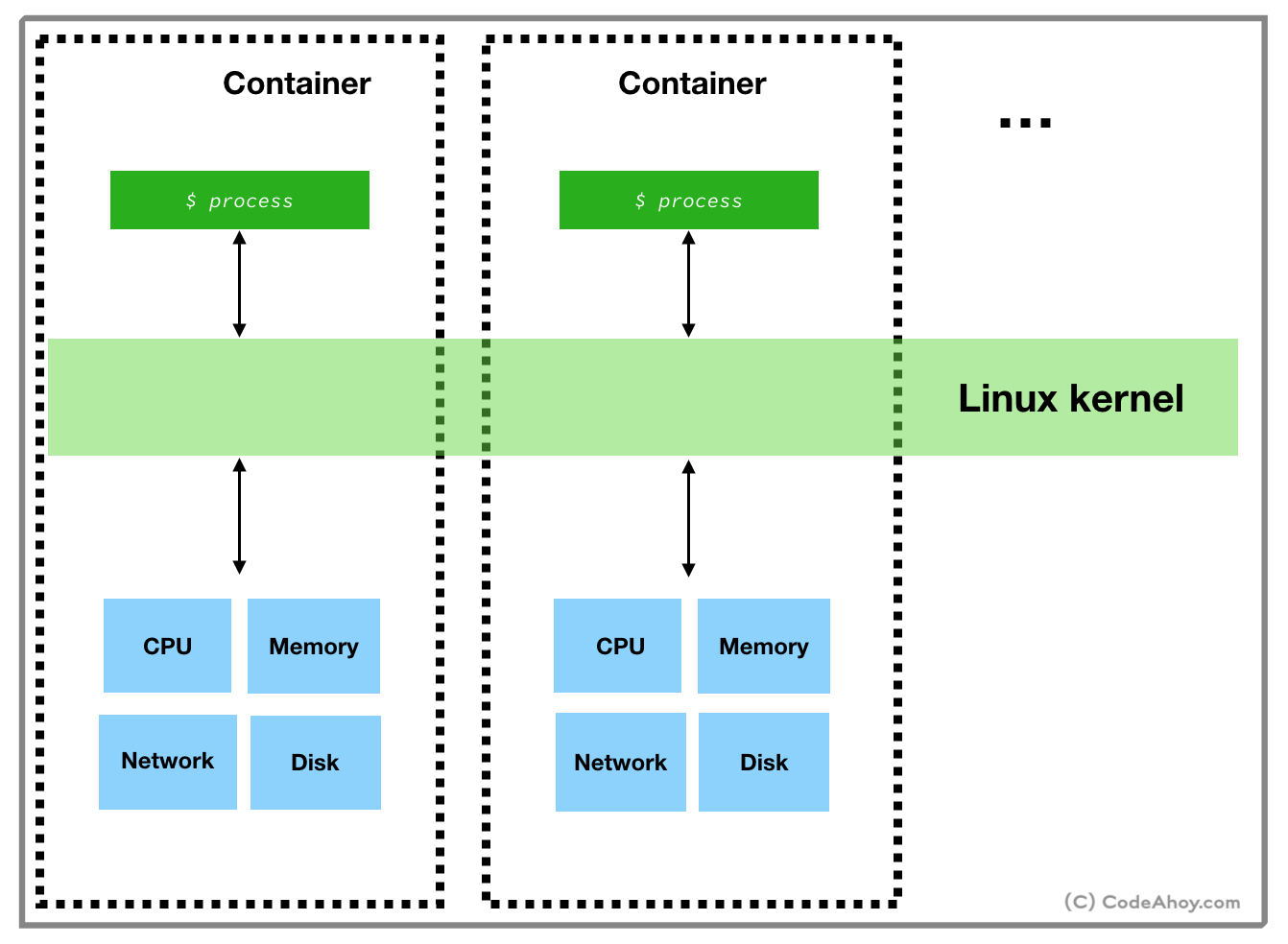
Compared to virtual machines, containers are light weight and faster because they make use of the underlying Linux OS to run natively in loosely isolated environments. A virtual machine hypervisor creates a very strong boundary to prevent applications from breaking out of it, where as containers’ boundaries are not as strong. Another difference is that since namespace and cgroups features are only available on Linux, containers can not run on other operating systems. At this point you might be wondering how Docker runs on macOS or Windows? Docker actually uses a little trick and installs a Linux virtual machines on non-Linux operating systems. It then runs containers inside the virtual machine.
Let’s put everything that we have learned so far and create and run a Docker container from scratch. If you don’t already have Docker installed on your machine, head over here to install. In our super made up example, we’ll create a Docker container, download a web server written in C, compile it, run it and then connect to the web server from our web browser (in other words, from host machine that’s running the container.)
We’l start where all Docker projects start. By creating a file called Dockerfile. This file contains instructions that tell Docker how to create a docker image that’s used for creating and running containers. Since, we didn’t discuss images, let’s take a look at the official definition:
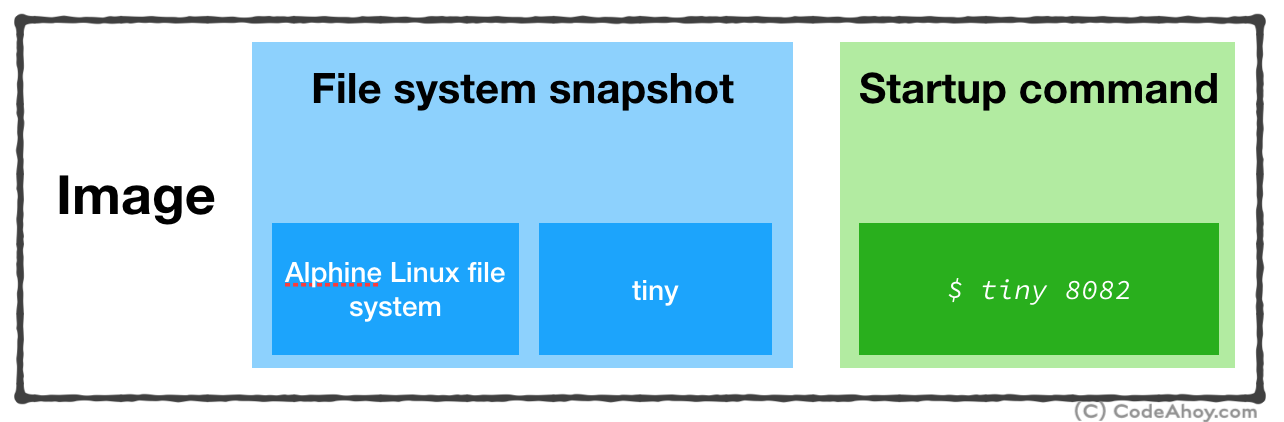
An image is an executable package that includes everything needed to run an application–the code, a runtime, libraries, environment variables, and configuration files. A container is a runtime instance of an image
Put simply, when you ask Docker to run a container, you must give it an image which contains:
- File system snapshot containing your application and all of its dependencies.
- A startup command to run when the container is launched.
Back to creating our Dockerfile so we can build an image. It’s extremely common in the Docker world to create images based on other images. For example, the official reds Docker image is based on ‘Debian’ file system snapshot (rootfs tarball), and installs on configures Redis on top of it.
In our example, we’ll base our image on Alpine Linux. When you see the term alpine in Docker, it usually means a stripped down, bare-essentials image. Alpine Linux image is about 5 MB in size!
Alright. Create a new folder (e.g. dockerprj) on your computer and then create a file called Dockerfile.
umermansoor:dockerprj$ touch Dockerfile
Paste the following in the Dockerfile.
# Use Alpine Linux rootfs tarball to base our image on
FROM alpine:3.9
# Set the working directory to be '/home'
WORKDIR '/home'
# Setup our application on container's file system
RUN wget http://www.cs.cmu.edu/afs/cs/academic/class/15213-s00/www/class28/tiny.c \
&& apk add build-base \
&& gcc tiny.c -o tiny \
&& echo 'Hello World' >> index.html
# Start the web server. This is container's entry point
CMD ["./tiny", "8082"]
# Expose port 8082
EXPOSE 8082
The Dockerfile above contains instructions for Docker to create an image. Essentially, we base our image on Alpine Linux (rootfs tarball) and set our working directory to be /home. Next, we downloaded, compiled and created an executable of a simple web server written in C. After, that we specify the command to be executed when container is run and expose container’s port 8082 to the host machine.
Now, let’s create the image. Running docker build in the same directory where you created Dockerfile should do the trick.
umermansoor:dockerprj$ docker build -t codeahoydocker .
If the command is successful, you should see something similar:
Successfully tagged codeahoydocker:latest
At this point, our image is created. It essentially contains:
- Filesystem snapshot (Alpine Linux and the web server we installed)
- Startup command (
./tiny 8092)
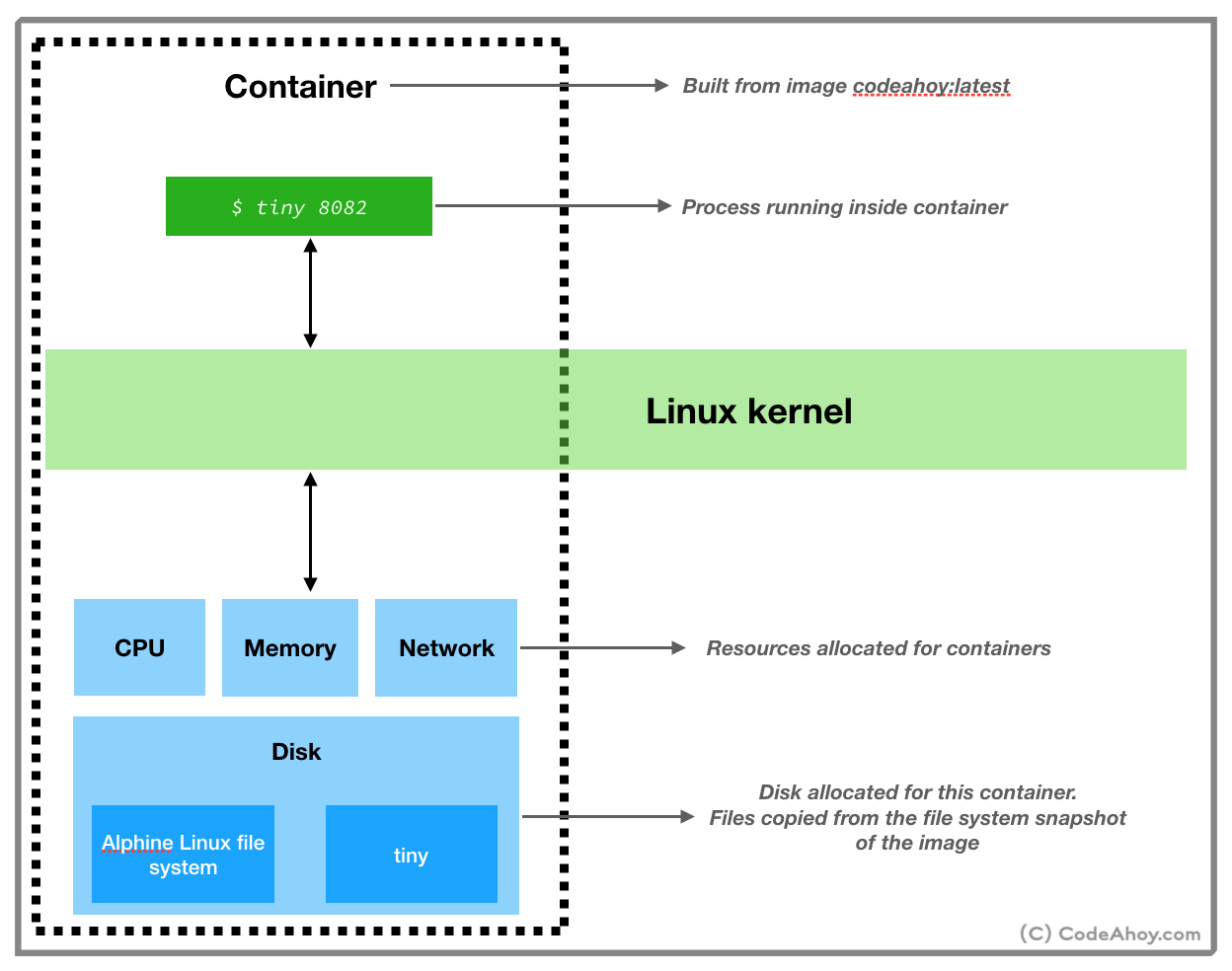
Now that we’ve created the image, we can build and run a container from this image. To do so, run the following command:
umermansoor:dockerprj$ docker run -p 8082:8082 codeahoydocker:latest
Let’s understand what’s going on here.
With docker run, we asked Docker to create and start a container from the codeahoydocker:latest image. -p 8082:8082 maps port 8082 of our local machine to port 8082 inside the container. (Remember, our web server inside the container is listening for connections on port 8082.) You’ll not see any output after this command which is totally fine. Switch to your web browser and navigate to localhost:8082/index.html. You should see Hello World message. (Instructions on how to delete the image and container to clean up will be in comments.)
In the end, I’d like to add that while Docker is awesome and it’s a good choice for most projects, I don’t use it everywhere. In our case, Docker combined with Kubernetes makes it really easy to deploy and manage backend microservices. We don’t have to worry about provisioning a new environment for each service, configurations, etc. On the other hand, for performance intensive applications, Docker may not be the best choice. One of the projects I worked on had to handle long-living TCP connections from mobile game clients (1000s per machine.) Docker networking presented a lot of issues and I just couldn’t get the performance out of it and didn’t use it for the project.
Hope this was helpful. Until next time.
 YAGNI, Cargo Cult and Overengineering - the Planes Won't Land Just Because You Built a Runway in Your Backyard
YAGNI, Cargo Cult and Overengineering - the Planes Won't Land Just Because You Built a Runway in Your Backyard
Comments (4)
Umer Mansoor
To delete the container and images setup in this blog post.
Get the container id by running:
docker container lsKill the container:
docker container kill [CONTAINER_ID]Remove the image:
docker image rm -f codeahoydocker:latestjustifiableedit
TL;DR: Docker is a buzzword label for a set of linux features used together with a management front end.
Krishnasamy
” Behind the scenes, when you ask Docker to run a container, it sets up a resource isolated environment on your machine. Then it copies over your packaged application and associated files to the filesystem inside the namespace. At this point, the environment setup is complete. Docker then executes the command that you specified and hands over the control.”
Thanks for this detail. I was looking for this kind of explanation all over the internet for almost one year to understand docker under the hood. Finally I got the answer. Now I can start to learn the docker. Thank you!!!!
deeMithan
This is probably the cleanest and crispiest explanation of containers I have seen.