
Caches are present everywhere: from the lowest to highest levels:
- There are hardware caches inside your processor cores (L1, L2, L3),
- Page/Disk cache that our Operating Systems
- Caches for databases such as using MemCached, Redis or DAX for DynamoDB
- API caches
- Layer-7 (Application layer) HTTP caches like Edge level caching in CDNs
- DNS caching
- Cache in your browser
- Microservices can have internal caches to improve their performance for complex and time consuming operations
- You are reading this post thanks to many intermediary caches
I can keep going but you get the point: Caching is ubiquitous. Which begs the question, why do we need caching? Before you scroll down for the answer, take a few seconds to think about the answer.
What is a Cache?
A cache is a fast data storage layer for storing a subset of data on a temporary basis for a duration of time. Caches are faster than original sources of data so they speed up future data retrievals by accessing the data in cache as opposed to fetching it from the actual storage location. Caches also make data retrievals efficient by avoiding complex or resource intensive operations to compute the data.
When the application needs data, it first checks if it exists in the cache. It if does, the data is read directly from the cache. If the data is not in cache, it is read from primary data store or generated by services. Once the data is fetched, it is stored in the cache so for future requests, it can be fetched from the cache.
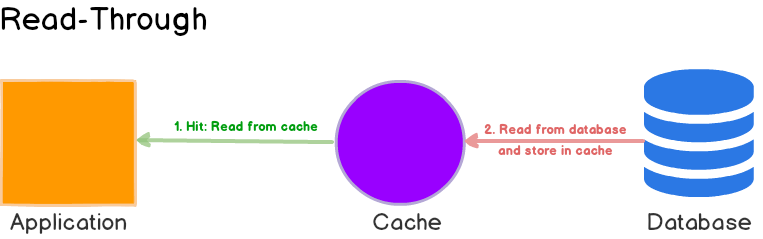
Why do we need Caching?
Typically, there are two main reasons for caching data:
- We cache things when the cost of generating some information is high (resource intensive) and we don’t need fresh information each time. We can calculate the information once, and then store it for a period of time and return the cached version to the users.
- Arguably the top reason why we use caching is to speed up data retrieval. Caches are faster than original sources of data and cached information can be retrieved quickly resulting in faster responses to users.
Caching Example
Let’s look at an example. Suppose we have a webpage that displays “Related Content” links on the sidebar. This related content is generated by machine learning algorithms by processing large volumes of data in the main database, and can take several seconds to compute.
- This is a complex and resource intensive operation: each user request has to calculate this information. For popular pages on the website, a significant amount of time and resources will be spent computing the same data over and over again. Impact: Increased load on backend servers and databases, and higher cloud infrastructure costs.
- Generating “Related Links” takes time and holds up the final response that’s sent to users. Impact: The response times increase that hurt user experience and page performance metrics such as the Core Web Vitals that search engines use.
To address both these issues, we can use a “Cache”. We can computed the Related Links once, then store it in the cache and return the cached copy for several hours or even days. The next time the data is requested, rather than performing a costly operation and waiting for several seconds for it to complete, the result can be fetched from cache and returned to users faster. (This type of caching strategy is called Cache Aside.)
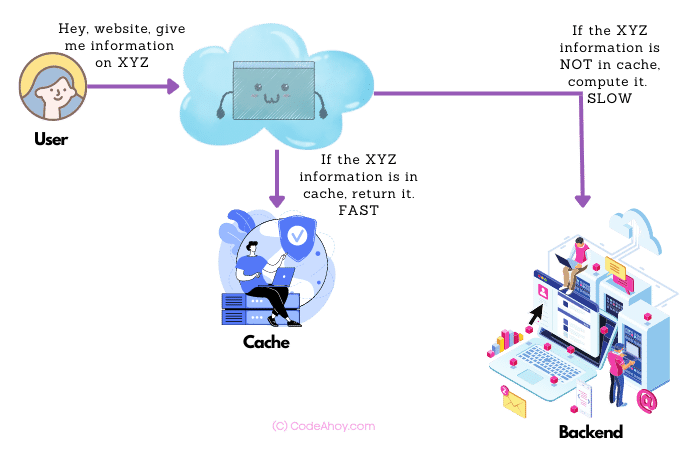
Why we use caching? Because it speeds up information delivery and reduces the cost of calculating that information over and over again.
Cache Invalidation
We have seen how useful caches can be: they save costs, scale heavy workloads, and reduce latency. But like all good things, there’s a catch or rather trade-offs that developers must be aware of.
Phil Karlton, an accomplished engineer who was an Architect at Netscape famously said the following which also happens to be my favorite quote:
There are only two hard things in Computer Science: cache invalidation and naming things - Phil Karlton
Cache invalidation is the process of marking the data in the cache as invalid. When the next request arrives, the corresponding invalid data must be treated as a cache-miss, forcing it to be generated from the original source (database or service.)
Caches are not the source of truth for your data. That’d be your database (or a service.) The problem happens when the data in your database (source of truth) changes, leaving invalid data in the cache. If the data is the cache is not invalidated, you’ll get inconsistent, conflicting or incorrect information. For example, suppose we cached the price of an item and the supplier increases it in their system.
Cache invalidation is indeed a hard problem. Why? Because we effectively need to deal with the dependency graph of all the inputs that gave us the result we cached. Any time even a single input changes, we have a stale or invalid result in the cache. Miss just one subtle place, and we have an issue. The program will still work making is very difficult to track down the exact issue and fix the cache invalidation logic. If you have a function with well defined inputs and outputs then it’s not that hard to catch issues. In fact, when it doesn’t work at all is usually one of the simpler things to find and fix. Cache invalidation bugs leading to the program “mostly working” makes somewhat trivial bugs fiendishly hard to discover.
Let revisit our earlier example of caching “Related Content” links (links to other related pages for a webpage.) Suppose one of the linked pages is no longer present in the system: it was taken down by an admin because of a complaint. We forgot to capture this input for cache invalidation. Now we get a “mostly working” system that results in users getting an HTTP 404 error when they click on a broken link. Debugging is very difficult because the actual page (that’s hosting the broken link) is not broken in any way. We only see HTTP 404 errors in the logs and troubleshooting turns into a nightmare.
In distributed systems with several inter-connected caches, invalidation becomes even more difficult thanks to many dependencies, race conditions and invalidating all the caches that need to be updated. Distributed caching has its own challenges at scale and some complex systems like Facebook’s Tao use cache leaders for handling invalidations for all data under their shards.
Heck, it is easy to run into cache issues during the course of normal software development. Modern CPUs have several cores and each has its own cache (L1) that’s periodically synced with the main memory (RAM). In the absence of proper synchronization, values stored in variables on one thread may not be visible to threads. For example:
foo = 2;
In Java, the JVM might update the value of foo in the local cache and not commit the result to memory. A thread running on another core may see a stale value for foo. (This is one of the primary reasons why writing multithreading applications is hard.)
In summary, caching is a super useful technique. But it can easily go wrong if we are not careful. When using a cache, it’s important to understand how and when to invalidate it and to build proper invalidation processes.
When to Not Use a Cache
Caches are not always the right choice. They may not add any value and in some cases, may actually degrade performance. Here are some questions you need to answer to determine if you need a cache or not.
- The original source of data is slow (e.g. a query that does complex JOINs in a relational database.)
- The data doesn’t need to change for each request (e.g. caching real-time sensor data that your car needs when it’s in the self-driving mode or live medical data from patients… not good ideas.)
- The operation to fetch the data must not have any side-effects (e.g. a Relational DB Transaction that fetches data and updated KPI counters is not a good caching candidate due to side-effect of updating counters.)
- The data is frequently accessed and needed more than once.
- Good cache hit:miss ratio and total cost of cache misses. For example, suppose I put a cache for user requests as they come in and it takes 10 ms to check if the data exists in the cache or not, vs the original time of 60 ms. If only 5% of requests are cached, I’m adding an additional 10ms to 95% of the requests that result in a cache-miss. Doing rough calculations, we can see that cache is actually hurting performance:
- Before cache:
1,000,000 requests * 60 milliseconds per request = 60,000,000 milliseconds total - After cache:
(0.05 * 1,000,000 * 10) + (0.95 * 1,000,000 * (60 + 10) ) = 67,000,000 milliseconds totalEach cache miss results in 60+10 millisecond That’s poorer than using no cache, assuming all requests are equal in value/distribution.
Caching Strategies
There are many different ways to configure and access caches. Various cache strategies that are covered in this post.
 How To Manage Employees Who Are Going Through a Difficult Period
How To Manage Employees Who Are Going Through a Difficult Period
Comments (2)
MysteryAjay
The quote is: there are 2 hard problems in computer science: cache invalidation, naming things, and off-by-1 errors.
JoeAnand
Your last sentence under “when not to use a cache” saved our bacon. Developers overused the Redis cluster, overusing it to the point that just 7pct requests were being fulfilled in cache. Very sure it reached the point where each request is being burdened with increased overhead. Wishing for better dashboards and monitoring from cache systems.