
According to Wikipedia, Semantic Search denotes search with meaning, as distinguished from lexical search where the search engine looks for literal matches of the query words or variants of them, without understanding the overall meaning of the query.
For example a user is searching for the term “jaguar.” A traditional keyword-based search engine might return results about the car manufacturer, the animal, or even the Jacksonville Jaguars football team. However, semantic search would analyze the context and intent behind the user’s query, such as whether they are interested in cars or wildlife, and then prioritize results accordingly.
In this blog post, we will explore the underlying principles of semantic search, discuss its advantages over other types of search, and examine real-world applications that are transforming the way we access and consume information.
Lexical Search Engines
Lexical (Traditional) search engines have served us well using keyword-based search methods, looking for matching exact words or phrases in users’ queries with those in documents/database. For example, if we search for the term “computer science intro” in a lexical / traditional search engine, it will return results that match one or more of my search terms.
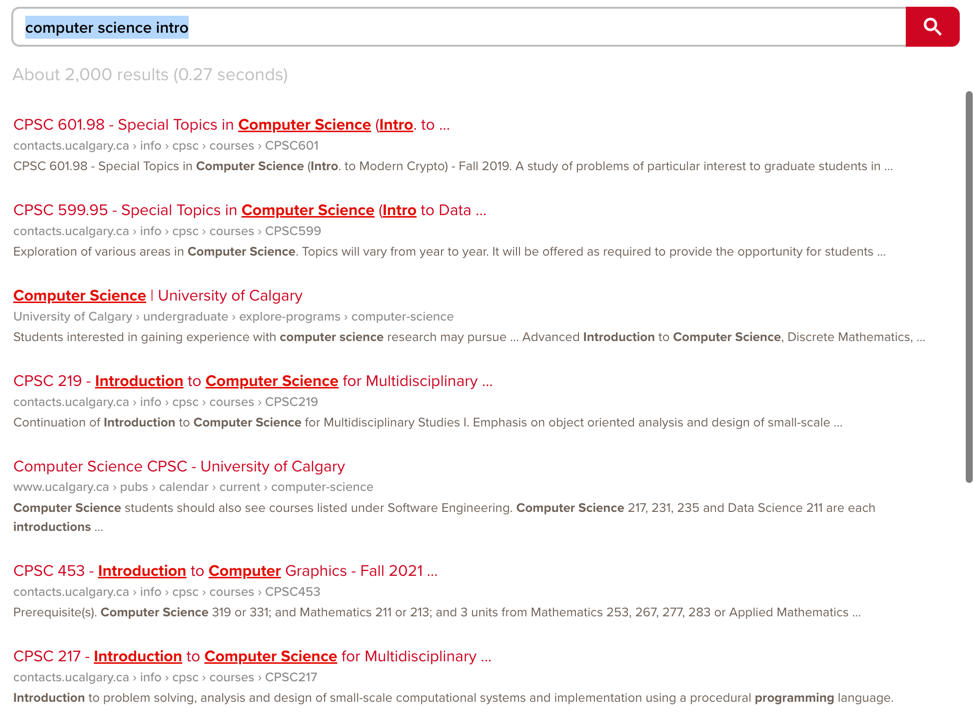
As you can imagine, the keyword matching approach often falls short when it comes to understanding what the user actually meant, often producing less accurate results.
Semantic Search
Enter semantic search — a context-aware search technology that aims to improve search results by focusing on understanding the meaning and context behind queries.
When a user inputs the query “computer science intro” in a semantic search engine, it would first attempt to understand the intent behind the query. In this case, the user is likely looking for introductory resources related to computer science. Based on this understanding, the search engine would prioritize search results such as introductory computer science courses or textbooks or other learning materials that cover fundamental topics in computer science.
NLP plays a crucial role in semantic search, as it provides the necessary tools and techniques to analyze the context and relationships between words in a query, ultimately helping the search engine understand the meaning and intent behind user queries.
Semantic search can also be implemented using embeddings and vector databases. In this approach, both the user query and the documents in the search database are represented as vectors in a multi-dimensional space. By comparing the distance between vectors, we can determine the most relevant results.
Word Embeddings
Word embeddings are a critical component in the development of semantic search engines and natural language processing (NLP) applications. They provide a way to represent words and phrases as numerical vectors in a high-dimensional space, capturing the semantic relationships between them. The key idea behind word embeddings is that similar words or phrases, like “big mac” and “cheeseburger,” should have closely related vector representations. This proximity in the vector space reflects their semantic relationship, enabling algorithms to better understand the meaning behind words and phrases.
There are several popular algorithms for generating word embeddings, including Word2Vec, GloVe, OpenAI embeddings and FastText. These algorithms work by analyzing large corpora of text data, learning the context and co-occurrence patterns of words, and then generating vector representations to capture these patterns. Words that often appear in similar contexts will have similar vector representations.
In short, word embeddings is powerful technique to represent words and phrases as numerical vectors. The key idea is that similar words have vectors in close proximity. Semantic search finds words or phrases by looking at the vector representation of the words and finding those that are close together in that multi-dimensional space.
For example, here’s how the process works in general if we use OpenAI Embeddings APIs for generating vector representations:
-
Document (or Dataset) embeddings: First, you would need to generate embeddings for the documents in your search database. You can use OpenAI embeddings to obtain these embeddings. Then you can store these vectors in a vector database or an efficient data structure like an approximate nearest neighbors (ANN) index.
-
Query embeddings: When a user submits a query, you’d call the GPT-3 API to generate an embedding for the query using the same method as the document embeddings. This returns a single query vector.
-
Similarity search: Compare the query vector to the document vectors stored in the vector database or ANN index. You can use cosine similarity, Euclidean distance, or other similarity metrics to rank the documents based on their proximity (or closeness) to the query vector in the high-dimensional space. The closer the document vector is to the query vector, the more relevant it is likely to be.
-
Retrieve and display results: Finally, retrieve the top-ranked documents sorted by their similarity scores and display them to the user as search results.
Keep in mind that this is a simplified example, and a full-fledged semantic search engine would involve additional considerations like query expansion, context-awareness, and other techniques to improve search results.
Word Embeddings Complete Example on Github
In the Python notebook linked below, we walk through the process of building a simple semantic search engine using word embeddings from OpenAI to illustrate basic concepts.
First let’s define our dataset of a few words that we’ll be searching against.
["hamburger", "cheeseburger", "blue", "fries", "vancouver", "karachi", "acura", "car", "weather", "biryani"]
dataset = pd.DataFrame(l, columns=['term'])
print(dataset)
This prints:
term
0 hamburger
1 cheeseburger
2 blue
3 fries
4 vancouver
5 karachi
6 acura
7 car
8 weather
9 biryani
Next, we covert our dataset to embeddings by calling the embeddings API of OpenAI and storing their vector representations in our “database” (dataframe.)
from openai.embeddings_utils import get_embedding
dataset['embedding'] = dataset['term'].apply(
lambda x: get_embedding(x, engine='text-embedding-ada-002')
)
# print terms and their embeddings side by side
print(dataset)
This outputs:
term embedding
0 hamburger [-0.01317964494228363, -0.001876765862107277, ...
1 cheeseburger [-0.01824556663632393, 0.00504859397187829, 0....
2 blue [0.005490605719387531, -0.007445123512297869, ...
3 fries [0.01848343200981617, -0.030745232477784157, -...
4 vancouver [-0.011030120775103569, -0.023991534486413002,...
5 karachi [-0.004611444193869829, -0.001336810179054737,...
6 acura [0.0055086081847548485, 0.013021569699048996, ...
7 car [-0.007495860103517771, -0.021644126623868942,...
8 weather [0.011580432765185833, -0.013912283815443516, ...
9 biryani [-0.009054498746991158, -0.015499519184231758,...
Now we are ready to search. We prompt user to enter a keyword. Once the user enters the keyword, we call the API to get its vector representation:
from openai.embeddings_utils import get_embedding
keyword = input('What do you want to search today? ')
keywordVector = get_embedding(
keyword, engine="text-embedding-ada-002"
)
# print embedings of our keyword
print(keywordVector)
To find the matching results, we iterate through the vectors of our dataset and apply cosine similarity to find the distance between keyword vector and each vector in the dataset. We printing top 3 results, sorted by the distance between vectors (keyword and dataset) in descending order.
from openai.embeddings_utils import cosine_similarity
dataset["distance"] = dataset['embedding'].apply(
lambda x: cosine_similarity(x, keywordVector)
)
dataset.sort_values(
"distance",
ascending=False
).head(3)
Here’s are the top 3 results for the keyword “big mac” from our dataset. As you can see, it correctly inferred that I was referring to a burger and found the right matches!
term distance
0 hamburger 0.853306
1 cheeseburger 0.841594
3 fries 0.823209
Here’s the complete code example:
 Brief Overview of Caching and Cache Invalidation
Brief Overview of Caching and Cache Invalidation