Related Books





Books / Ruby for Beginners / Chapter 24
Hash Class in Ruby
Hash
Hash data structure has many names: hash, hash table, map, dictionary, and even object in JavaScript. Hash and array are essential data structures for any programmer. These data structures are different, but they were designed for the same goal: to store and retrieve data. The only difference is how these two operations are implemented.
What is array and how do we store and get the data back from array? Imagine that a kid has lots of items (toys). Mother put all these toys to a single shelf and assigned sequential number (1, 2, 3 and so on). We need to visually scan the entire shelf if we want to find our favorite toy. It can take some time if this shelf is long enough. However, we can easily find a toy if we know its number.
Hash looks like a magic bucket. There is no any order, and we don’t know how it works. You can put any object to this magic bucket and assign a name: “Hey, magic bucket, here is a ball”. We can also get any object from it: “Hey, magic bucket, give me this thing called ball”. Important detail is that we name things, and use this name to get objects back. This name is the key (or hash key). And item lookup happens in constant time, immediately.
But how does this magic bucket work? Why in the case of array we have to scan the entire shelf while magic bucket takes no time1? Secret is its inner organization and how it works under the hood: there are multiple small buckets (“bucket” is the actual name for inner structure), and object goes to specific small bucket, depending on its characteristics (let’s say, color). More objects require more inner buckets to be present.
If the hashes are so good, why not always use them?
First, this data structure does not guarantee any order. If we add data to an array using “push”, we know exactly which element was added first, which one after. But there is no order in the hash once value is there, also there is no way to tell when it got there.
Note: although the hash data structure doesn’t guarantee any order, order is guaranteed by Ruby hash implementation (however, the authors wouldn’t recommend relying on it). This is what the official documentation at https://ruby-doc.org/core-2.5.1/Hash.html says:
Hashes enumerate their values in the order that the corresponding keys were inserted.
But since any web developer should know JavaScript at least at a minimum level, let’s see what the documentation on JS says about it:
An object is a member of the type Object. It is an unordered collection of properties each of which contains a primitive value, object, or function
However, in the newer version of JavaScript (ES6 and above), the Map class (one of hash implementations) will return values from the hash in the order. So rule of thumb here is not to rely on the hash order.
Secondly, for every data structure there is such a concept as “the worst time of execution”. In case of Hash it is linear time, O(N): the code will scan through all the elements. But in case of arrays, lookup by index2 always takes constant time, O(1). So if we’re okay with using indexes (like 0, 1, 2) instead of keys (like :red, :green, :blue), then it’s better to use arrays, it’s guaranteed to be faster.
However, the worst cases are not common in practice, and the main reason programmers use hashes is convenience for a human being. It is much easier to say “get the ball” than “get the object by index 148”.
To define a hash in a Ruby program we need use curly brackets (square brackets are used for arrays):
$ pry
> obj = {}
...
> obj.class
Hash < Object
Don’t name your variable “hash”, because it is a reserved language keyword (but you can enter it into the REPL and see what happens). That’s why the authors normally use “obj” (object) or “hh” (double “h” says it’s more than just a variable).
Programmers say that the hash is a key-value storage, where each key is assigned a value. For example, the key is a “ball” (string), and the value is the physical object “ball” itself. The hash is often called “dictionary”. This is partly true, because the dictionary of words is a perfect example of hash. Each key (word) has a meaning (description of the word and/or translation). In the Java language hash used to be called “dictionary” too, but since the seventh version this concept has become obsolete and the dictionary has been renamed into “map”3.
The key and value in the hash can be any object, but most often the key is a String (or Symbol), and the value is… The value is the actual object, it is difficult to predict what it will be. It can be a string, a Symbol, an array, a number, another hash. So when developers define a hash in a Ruby program, they normally know in advance what type it will keep.
For example, let’s agree that the key in the hash is Symbol, and the value is a number (type Integer). We’ll keep the weight of different types of balls (in grams) inside of our hash:
obj = {}
obj[:soccer_ball] = 410
obj[:tennis_ball] = 58
obj[:golf_ball] = 45
If you write this program into the REPL and type “obj”, you will see the following:
{
:soccer_ball => 410,
:tennis_ball => 58,
:golf_ball => 45
}
Text above is perfectly valid from the Ruby’s language perspective, and we could initialize our hash without writing the values (without using assignment operator “=”):
obj = {
:soccer_ball => 410,
:tennis_ball => 58,
:golf_ball => 45
}
The operator “=>” in Ruby is called “hash rocket” (in JavaScript “fat arrow”, but has a different meaning). However, the “hash rocket” notation is now obsolete. It would be more correct to write the program this way:
obj = {
soccer_ball: 410,
tennis_ball: 58,
golf_ball: 45
}
Pay attention that despite the fact that the record looks different, if we write “obj” in REPL, we will get the same conclusion as above. In other words, the keys (:soccer_ball, :tennis_ball, :golf_ball) are Symbol types in this case.
To get the value back from the hash, use the following construction:
puts 'Golf ball weight:'
puts obj[:golf_ball]
So you access hash very similar to array, but instead of index you use the key. Compare:
arr[4]
obj[:golf_ball]
Keep in mind that symbols (Symbol) are not strings (String). Consider the following example where we add two entries (with the same value of 45), they visually look very similar, but in practice hash will keep two different objects:
obj = {}
obj[:golf_ball] = 45
obj['golf_ball'] = 45
Hash above is initialized with two key-value pairs. First key has the type of Symbol, and the second has the type of String:
{ :golf_ball => 45, "golf_ball" => 45 }
Exercise 1 Using the hash below write a program that transforms the hash to the Moon conditions. It’s known that weights on the Moon are 6 times less than weights on the Earth:
obj = {
soccer_ball: 410,
tennis_ball: 58,
golf_ball: 45
}
Exercise 2, the Moon store Using the hash from the previous exercise write a program that for every type of the ball above will ask the number of items user wants to buy. User should be able to type the number from a console. At the end program should calculate the weight of all items in the cart. Also, program should print both weights: for Moon and Earth.
Other types as Hash values
In previous chapter we figured out that hash is a set of key-value pairs, where key is usually Symbol or String and value is an object. We used the type Integer in our examples. However, there is no any limitation here and we can use any types for keys and values, including strings, arrays, and even other hashes!
It’s the same for arrays. Array elements can be numbers, strings, array themselves (in this case we’ll get two-dimensional arrays), and even hashes. And these hashes can contain other hashes and other arrays. In other words we can use any combination of arrays and hashes, and create deeply nested data structure called JSON (JavaScript Object Notation - we’ve already mentioned that the hash in JavaScript is often called “object”). Despite the fact that this acronym originates from JavaScript, it is also widely used in Ruby.
Here is how this combination might look like:
obj = {
soccer_ball: { weight: 410, colors: [:red, :blue] },
tennis_ball: { weight: 58, colors: [:yellow, :white] },
golf_ball: { weight: 45, colors: [:white] }
}
Let’s break down the code above into smaller parts. Here is the top-level hash:
obj = {
... this is the hash ...
}
For every key in the hash above we define another hash, like:
obj = {
soccer_ball: { ...this is the hash... },
tennis_ball: { ...this is another hash... },
golf_ball: { ...and another hash... }
}
And all of these three hashes have the following keys and corresponding values:
- Key
:weight(Symbol), value type:Array - Key
:colors(Symbol), value type:Array
Note the :golf_ball hash, it has :colors key with the type of Array, but technically it can be written as follows:
golf_ball: { weight: 45, color: :white }
We’ve intentionally chosen the Array type initially, it was a programmer’s choice. Ruby allows any syntax, but our decision was to to keep the structure (or schema). We’re doing this for the following reasons:
- To avoid ambiguity. Every line looks similar.
- To keep array of “colors”, so we can add another color in the future. It’s a good example of how programmers plan their programs. They have option of choosing any type, but what works better now and what will work better in the future? Is there any information that indicates that we might need this or another type in the future? In our case we have this information - all previous records have more than one color.
- To keep the code simple. We’re not talking about existing code, but about the code that traverses a data structure. If data structure is uniform, the code is going to be more simple, because there won’t be any special/edge cases like handling two different types for the same purpose.
In other words, often JSON objects have schema, well-defined structure. But how one can access such a nested object? Well, the same way we access arrays and hashes, but combining these access operations. Let’s print all the colors for the tennis ball:
arr = obj[:tennis_ball][:colors]
puts arr
Weight for the golf ball:
weight = obj[:golf_ball][:weight]
puts weight
Add new “:green” color to array of colors for the tennis ball:
obj[:tennis_ball][:colors].push(:green)
Structure we defined above starts with curly bracket. It means that JSON object has the type of Hash. But JSON objects can be arrays too. It depends on your application requirements. If the primary goal of our application is to print a list (we don’t need any random access to update or read the hash), JSON object above can be represented the other way:
obj = [
{ type: :soccer_ball, weight: 410, colors: [:red, :blue] },
{ type: :tennis_ball, weight: 58, colors: [:yellow, :white] },
{ type: :golf_ball, weight: 45, colors: [:white] }
]
The structure above is nothing else, but a array of objects with some properties (keys):
obj = [ {}, {}, {} ]
Depending on requirements a programmer defines the right representation of data.
Exercise 1 Online store defines a shopping cart the following way (
qtyis the quantity of items):
cart = [
{ type: :soccer_ball, qty: 2 },
{ type: :tennis_ball, qty: 3 }
]
And the warehouse availability is defined by the following hash:
inventory = {
soccer_ball: { available: 2, price_per_item: 100 },
tennis_ball: { available: 1, price_per_item: 30 },
golf_ball: { available: 5, price_per_item: 5 }
}
Write a program that prints the total price of all items in the cart, and also informs if there is enough items at warehouse. Try to change cart and inventory and see if your program works correctly.
JSON-structure of a real-world application
JSON-structure is a universal way of describing almost any data. For example, the following hash describes the state of UI4 of minimalistic TODO-list application:
{
todos: [{
text: 'Eat donut',
completed: true
}, {
text: 'Go to gym',
completed: false
}],
visibility_fiter: :show_completed
}
UI part of the app may look like this:
<img src=”/img/books/ruby/064-01-fs8.png” class=”rounded mx-auto d-block” alt=”To-Do app, first item is visible, “Show completed” switch is on”>
If we break down this data structure, we’ll see that there is no magic:
{
todos: [ { ... }, { ... }, ... ],
visibility_fiter: :show_completed
}
Value by the key of :todos is Array. Every element of the array is hash (object), which has two properties: 1) text 2) completion flag (Boolean type which is either true or false). Root level hash has also :visibility_filter key with corresponding value of :show_completed. It’s up to developer to pick the right naming for hash keys or values. We just assume that somewhere some part of our program will be responsible for filtering out items based on the value of the filter. That’s why we have two items in todos-array, but show only one on the mockup above.
When we turn off the switch, the UI will look different:
<img src=”/img/books/ruby/064-02-fs8.png” class=”rounded mx-auto d-block” alt=”To-Do app, all items are visible, “Show completed” switch is off”>
And the state of the program will be represented by slightly different hash:
{
todos: [{
text: 'Eat donut',
completed: true
}, {
text: 'Go to gym',
completed: false
}],
visibility_fiter: :show_all
}
When we want to add an item (“Call mom” below), we just push this element to “todos” array:
{
todos: [{
text: 'Eat donut',
completed: true
}, {
text: 'Go to gym',
completed: false
}, {
text: 'Call mom',
completed: false
}],
visibility_fiter: :show_all
}
So the last item gets reflected in UI:

Exercise 1 Create a JSON structure to represent the state of the following online-banking account:
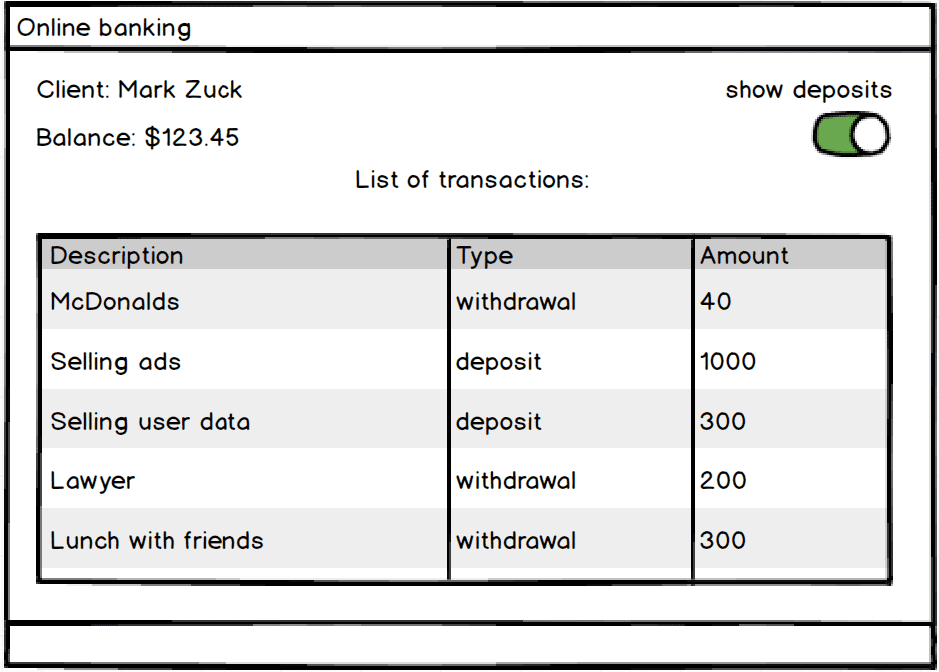
Exercise 2 Write a program that accepts hash you created in Exercise 1 and prints the result to the screen. Make sure that switch above works and the program doesn’t show any deposits if the switch is off.
English-Spanish dictionary
Let’s practice to sum up everything we know about hashes, arrays, and their combinations. We’re going to build minimalistic English-Spanish dictionary application. You can guess from the title which data structure we’ll be using: hash (also known as dictionary, or hash map, or “object” in JavaScript).
The most important thing here is database. We won’t be using sophisticated database management systems like Postgres, MySQL, etc. But we’ll keep data organized in the data structure in computer’s memory. It could look like this:
dict = {
'cat' => 'gato',
'dog' => 'perro',
'girl' => 'chica'
}
We’re saying “it could look like” because there is no single opinion at this time. Feel free to use any other data structure. In our case it’s going to be a set of key-value pairs, where key is English word (String type), and value is translation (Spanish word, String type).
Hash data structure allows to perform fast lookups in our database. “Fast” here means lookups in constant time (or O(1)). Simply put, no matter how many words do we have in hash, lookup time is going to be about the same.
Compare this approach to arrays. We still can solve this problem using arrays, however there are few caveats. Here is how the code would look like:
arr = [
{ word: 'cat', translation: 'gato' },
{ word: 'dog', translation: 'perro' },
{ word: 'girl', translation: 'chica' }
]
But to find element in array we’ll need to iterate over the each element and perform comparison. More elements we have, more time we need for lookups. In other words, the number of elements we need to check grows along with the size of array. Computer Science says the search complexity takes linear time, O(N) (where N is the number of elements).
In real life you probably won’t notice this difference for small number of elements. Moreover, newer versions of Ruby language use arrays instead of hashes for 7 elements or below! We won’t see it though, because normally programmers don’t need to poke around with a language internals. However, anyone can open up Ruby language implementation (which is written with C) and confirm that.
Anyway, hash serves better for our purposes. By using this or another data structure we demonstrate our intention to other programmers: “we’re using this specific data structure, and we assume that we’re going to use this data structure specific way”. The way you implement your programs will “dance” around decisions you made at the very beginning, and picking the right data structure is the most important step.
One can look up an element in array by simply providing an index, which is a number ranging from zero to the size of array. In case of dictionary application we don’t know these numbers, we know words. We have a key word, and we need to find out the value word. Here is how you perform lookups in the hash:
dict[input]
Here is how minimalistic application would look like:
dict = {
'cat' => 'gato',
'dog' => 'perro',
'girl' => 'chica'
}
print 'Type a word to translate: '
input = gets.chomp
puts "Translation to Spanish: #{dict[input]}"
Result:
Type a word to translate: dog
Translation to Spanish: perro
Keep in mind that we have one-way dictionary only, it’s English-Spanish. You can’t use it reverse to lookup Spanish words, because you access a hash by the key, not by value. There is no any way for reverse-lookup in hashes. The only workaround to create another, reverse-hash for this specific purpose, where keys are Spanish words and values are English ones.
Constant O(1) and linear O(N) times are definitions from Computer Science. Beginner programmers don’t need to know all the details, but it’s always important to ask yourself - what would be the time complexity if I implement my program this way, is this approach going to be efficient? Time and space complexities for all popular data structures could be found in the Poster of common algorithms used in Computer Science
For example, you can see that the average time complexity to search in array is linear O(N); while for hashes it is constant O(1):
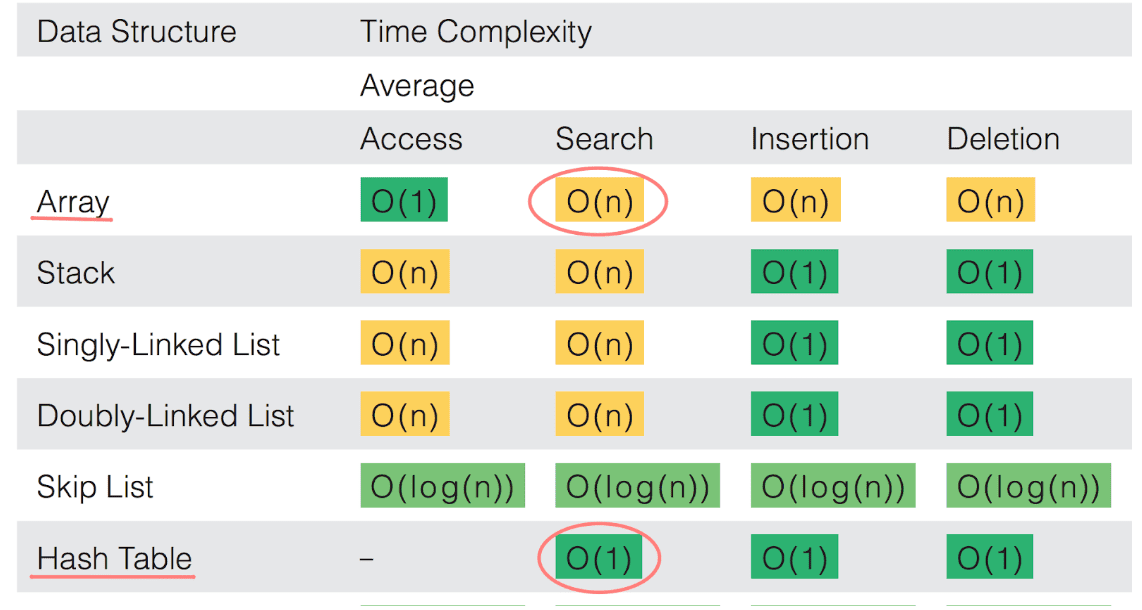
Exercise 1 Implement sophisticated English-Spanish dictionary, where one English word is represented by multiple Spanish translations.
Exercise 2 Implement your own phone book. For every record (key is the last name) specify three additional parameters: email, cell_phone, work_phone. Program should ask for the last name and show contact info.
Most often used methods of Hash class
In general, “Hash” data structure is pretty straightforward. Ruby language has some methods of Hash class that you will probably see in other languages as well. Here is how, for example, hash access looks like in JavaScript:
$ node
> hh = {};
{}
> hh['something'] = 'blabla';
'blabla'
> hh
{ something: 'blabla' }
Difference is that JavaScript doesn’t have Symbol type, and most of the time strings are used as hash keys. Compare Ruby to JavaScript.
Ruby:
hh[:something]
or (also valid syntax):
hh['something']
JavaScript:
hh['something']
Hash is the data structure that is also implemented in other tools, for example, in databases. Well-known Redis database is nothing but sophisticated key-value storage. In previous chapters we’ve implemented a phone book. But imagine that we need to persist this data on application restart. We have a couple of ways to do that. For example, we can save (serialize) this information into a file. This approach works great, but it can be a little bit slow when you have millions of records. Another approach is to use this NoSQL database, central storage operated by Redis through an API (Application Program Interface).
No matter what exactly you’re using, either some sort of library (gem), data base, or plain old Ruby language (or even other programming language), interface for Hash access remains the same:
- “
get(key)” - gets the value - “
set(key, value)” - set the value for a specific key
Documentation for Redis database has similar example:
redis.set("mykey", "hello world")
# => "OK"
redis.get("mykey")
# => "hello world"
Wikipedia says that Redis is nothing but a key-value store:
Redis is… key-value store…
Curious reader might ask “why do I need Redis while we have hash data structure implemented in Ruby, and it is represented by Hash class?” Well, Hash in Ruby language doesn’t keep the data on disk, so every time you restart your program, all the data you stored in hash goes away. For example, your phone book application isn’t very useful because of that - you can keep the program running, but if you need to restart your computer you’ll need to type in your phone records again. The second reason is that Redis was designed to keep millions and millions of key-value pairs efficiently. And normally we don’t keep that number of records in simple hash in Ruby language (or any other language).
Below we’ll take a look at the most often used methods of Hash class. All of these methods are also explained in documentation.
Setting a default value in Hash
It is often useful to have default values in a hash. You might even want to make a bookmark, since that trick can be used while solving interview questions. We’ll take a look at one of these questions.
Given a sentence calculate the usage frequency for each word. For example, there are two words “the” in the sentence, one “dog”, and so on. How do we solve this problem?
Imagine we have a string “the quick brown fox jumps over the lazy dog”, let’s split this string into array, so we have array of words for this sentence:
str = 'the quick brown fox jumps over the lazy dog'
arr = str.split(' ')
We have array of words in “arr” variable, let’s traverse the array and put each element into a hash, where hash key is the word itself, and the value is the counter. As the first step we will just set this counter to one (1) for every word:
hh = {}
arr.each do |word|
hh[word] = 1
end
However, we don’t want to set the counter to one (“1”), since we want to calculate the number of occurrences of every word in a sentence. So we need to increase the counter by one. We can’s just do “hh[word] += 1” (or “hh[word] = hh[word] + 1”), because if the word is not present in the hash, we’ll get the following error:
NoMethodError: undefined method `+' for nil:NilClass
In other words, “plus” operation isn’t applicable to nils. So we need to perform a comparison: if the word is already in the hash, increase the counter by one. Otherwise, just add this word with initial counter value (which is one):
arr.each do |word|
if hh[word].nil?
hh[word] = 1
else
hh[word] += 1
end
end
Here is how full application listing would look like:
str = 'the quick brown fox jumps over the lazy dog'
arr = str.split(' ')
hh = {}
arr.each do |word|
if hh[word].nil?
hh[word] = 1
else
hh[word] += 1
end
end
puts hh.inspect
Program above works as expected, and here is the result:
{"the"=>2, "quick"=>1, "brown"=>1, "fox"=>1, "jumps"=>1, "over"=>1, "lazy"=>1, "dog"=>1}
Readability of the program above can be improved if we could set the initial (default) value for the hash, for example:
str = 'the quick brown fox jumps over the lazy dog'
arr = str.split(' ')
hh = Hash.new(0)
arr.each do |word|
hh[word] += 1
end
puts hh.inspect
Nine lines of code instead of thirteen!
But what exactly “Hash.new(0)” means? It has two parts:
Hash.new- initializing hash, compare it to the shorter alternative:{}Hash.new(0)- providing parameter while creating an instance of a Hash class (we’ll cover what “creating instance” is in the next chapters). In this case “0” is the parameter and initial value for default hash values.
Exercise Create a program that calculates the number of occurrences of different letters (characters, not words) for the given sentence and prints result to the screen.
-
“No time” is technically incorrect, text was simplified for readability. Correct reading is “better time” or “logarithmic time”. Scanning of an array is linear operation, and it takes 1,000,000 iterations (worst case) to find the element in 1,000,000 array. However, “binary search” takes logarithmic time and allows to find element in almost 20 (!) iterations for 1,000,000 items array. ↩
-
Lookup by index is just accessing array by index, like
arr[4]to get the fifth element. ↩ -
https://docs.oracle.com/javase/7/docs/api/java/util/Dictionary.html ↩
-
User Interface ↩