Related Books





Books / Ruby for Beginners / Chapter 43
Testing Ruby programs
What is software testing? The definition is quite broad, therefore there is plenty of testing methodologies exist.
Imagine a hardware engineer just built the radio from a set of components, and wants to understand if it works or not. She’ll probably use so called smoke testing, when you turn on and off the power supply quickly to see if there isn’t any smoke, to find out there is no fundamental failures. If there is no any smoke, one can proceed to “happy path” testing, turning on the radio, and trying to tune it in to some radio station to check if there is any sound.
There can be other tests before the radio goes for production. For example, load testing to measure the electricity consumption. The radio probably should be power-efficient, so people won’t need to change batteries every day. Even if the radio works, and there is a sound, battery drain problem can be a marketing failure, and the product won’t succeed.
Some tests can involve assembly testing, so it works as expected over extended period of time when it is installed inside of a truck or any other vehicle. The number and depth of these tests depend on requirements. Are we just building pocket radio or military-grade radio? Answers to this fundamental questions define the product quality, and define the testing methodologies we’re going to use.
The same is true in software testing. There are numerous of testing methodologies, like manual testing, automated testing, unit testing, integration, load, and so on. It takes a lot of time to get familiar with all of these concepts, each methodology is probably represented by hundreds of books. We’ll take a look into the most popular tests software developers face on their day-to-day basis: unit tests. What are unit tests and why there is a need for them?
About 30 years ago almost nobody was looking at software testing like at something important. Programs were made in text editors, and folks used to just run them (or send to their clients on floppy disks, CD-ROMs and later through Internet). In case of an error or incorrect behavior programmers used to fix the software and ship the new release. Normally, these releases included a set of bug fixes.
However, complexity of software products was increasing. The number of developers in a teams was increasing. Often a small change could introduce a bug. For sure, some number of these bugs used to get caught by manual testing (or testers). However, it was not enough.
The question of identifying bugs on early stages has emerged. If there is a software module, or critical unit, is it possible to make it fool-proof, so it will be harder to break? It’s like in real life, morning routine says to double check the iron and stove are off before you go to work. You are almost certain that these are off, but the price to verify that is almost nothing compared to the damage it can cause in case something is not right.
The same is true for programming:
- Instead of checking the iron or gas stove, we double check software units of the same program.
- Instead of checking it only once, programmers run automated checks after every change.
Will you agree that it’s much easier? Software developers change their programs, run tests, and make sure that everything works as expected. If something breaks, one can fix it right away, without shipping a software to end users and releasing broken version to production. So identifying bugs is a matter of seconds or minutes (for example, running 500 automated tests normally takes a couple of minutes), not days.
For a relatively simple project, for every 100 changes we’ll run 500 tests for each, which gives about 50 thousand test runs. As you can imagine, it’s much harder to introduce bugs having tests culture on a project in place, and software quality improves dramatically. However, unit-testing is not free.
Engineers need to write these tests. While writing tests isn’t hard, it requires time, and businesses need to invest time and money into tests. Good tests require the knowledge of testing frameworks, testing methodologies, and some experience writing these tests.
At the same time it’s not possible to cover absolutely everything with tests. Ten if...else statements in your program are 2 (number of possible branches for each statement) in the power of 10 (number of statements) code flow combinations, 1024 total for such a small number of conditions.
Some programs use “code coverage” term, represented in percentage. You can hear something like “the code coverage for our project is 80%”, which is often something to be proud about. The question though is how this number was calculated. Yes, some modules can be covered with tests pretty extensively. But even with 100% coverage, the number of possible ways of how a real-life program can be executed is much more than the number of tests (assuming the program has at least a thousand lines of code).
Also, developers often create tests as soon as they write some code. But on initial stages, the software design often isn’t fixed. Programmers do experiment as artists do multiple sketches before in putting the final details to a landscape drawing. Making design final at the first attempt is close to impossible. And good amount of unit tests fix application design at the stage when it is still fresh.
With removing unnecessary code one needs to remove related tests. From a business perspective you are doubling your expenses while getting rid of something you’ve spent money on.
With all these cons, unit testing is no question practice that greatly improved software quality. Businesses understand the value, and heavily invest in building reliable software solutions. Unit testing is a standard, and there is no any software frameworks that don’t come with built-in test tools today. In the next chapter we’ll take a closer look into popular testing framework for Ruby called “Rspec”.
Rspec
According to The Ruby Toolbox website, Rspec is the most popular testing library for Ruby:
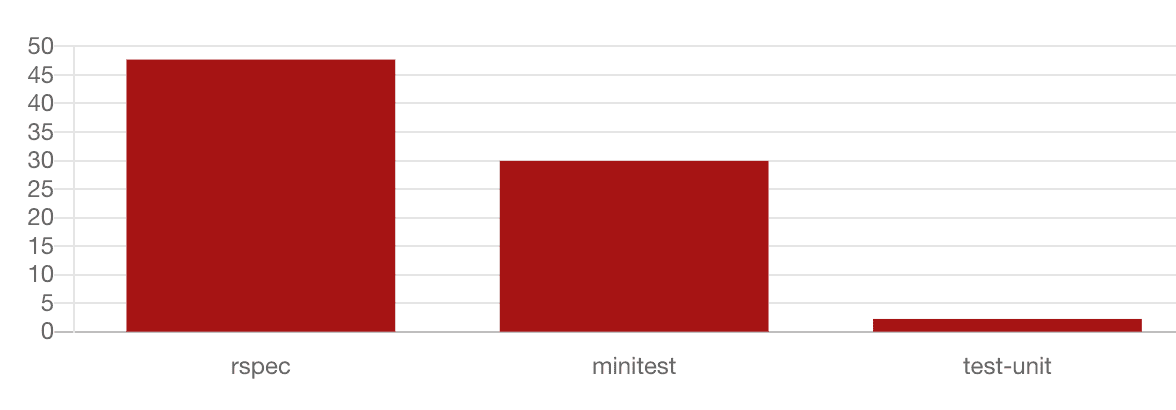
Some folks from Ruby community don’t like it though:
RSpec offends me aesthetically with no discernible benefit for its added complexity over test/unit.
It’s actually a matter of preference, the question is quite controversial. To some degree DHH is right, RSpec often emphasizes the smart, not simple way of writing tests. It feels like a sports car changing lanes fast on a highway, but at the end result is about the same.
The Rspec configuration can take up some time, the good news is that Rspec has completed its maturing phase, and configuration is rather simple, and for almost every question there is an answer you can search online.
In reality, the readability (and developer happiness) of tests solely depends on a team. A development tool is not the first factor here. There is no such tool that solves all the problems, and any tool can be misused. The question is more about balance and producing simple and readable tests rather than smart tests.
Rspec is based on its own DSL - domain-specific language. Read it as “language extensions”. Rspec introduces few new keywords, like “describe”, “let”, “it”, “before”, “after” and so on. We haven’t covered any DSL in this book before, so let’s just assume it’s a new language syntax that you need to be familiar with.
We are going to install and configure Rspec from scratch. Let’s start with a latest Ruby, type “rvm list known” to get the list of available rubies for download. We need “MRI” flavor (Matz’s Ruby Interpreter - classic Ruby developed by Yukihiro Matsumoto). Once you get the version, type the command to install:
$ rvm install 2.7.0
Or any other version without “-preview” suffix. Then let’s create a directory and fix the Ruby version for this directory:
$ mkdir rspec_demo
$ cd rspec_demo
$ echo "2.7.0" > .ruby-version
Make sure you have the version you expect:
$ ruby -v
ruby 2.7.0p0 (2019-12-25 revision 647ee6f091) [x86_64-darwin16]
If the version is different, do cd-trick. Change directory to one level up and switch back, that’s how some Ruby version managers work, they hijack your “cd” command:
$ cd ..
$ cd rspec_demo
In previous chapters we were using “gem install...” command to download and use Ruby libraries from Internet. Once a library gets downloaded, it will be located somewhere on the disk, and programs can use it. However, it’s nice if we can keep a list of dependencies somewhere. Like “hey, here is our program, but it depends on this, this and this, you must download these libraries, so the program works file”.
“Gemfile” is such mechanism. It’s just a list of libraries, with some features. For example, you can specify a source, or you can stick to particular version of a library. Imagine new versions gets released, and API (the way you use the library) changes. You still want your old program to work, right? Let’s create new “Gemfile”:
$ bundle init
Here is how default “Gemfile” looks like:
# frozen_string_literal: true
source "https://rubygems.org"
git_source(:github) {|repo_name| "https://github.com/#{repo_name}" }
# gem "rails"
Looks a bit scary, but at the moment we need only one line that defines a place where to look for gems. We’ll keep the “source ...” line and add “rspec” dependency. So here is how your “Gemfile” should look like:
source "https://rubygems.org"
gem "rspec"
And we can run “bundle”. Basically this command will execute “gem install ...” for every gem located in “Gemfile” (we have only one at the moment):
$ bundle
Fetching gem metadata from https://rubygems.org/...
Resolving dependencies...
...
Fetching rspec 3.9.0
Installing rspec 3.9.0
Bundle complete! 1 Gemfile dependency, 7 gems now installed.
Use `bundle info [gemname]` to see where a bundled gem is installed.
If you “ls” in the directory, you’ll see “Gemfile.lock” which was created automatically. You’re not supposed to modify this file with your code editor, it gets updated automatically by “bundle” command if needed. Lock-file locks your application to specific version of library, so the app will work forever. Imagine in 30 years from now you’ll need to execute the same program. Your “Gemfile.lock” comes into play and says: “I don’t care which year it is now, and I don’t care about any newly released software, I need to download these versions from Internet”. Unless you explicitly update your dependencies, you’ll stick to the specific version of Rspec (or any other library).
You should have three files in your directory: “.ruby-version”, “Gemfile”, and “Gemfile.lock”. Type “ls -a” to get the full list. Yes, you need to specify “-a” (all) parameter, so the list has hidden (dot) files as well, including “.ruby-version”.
If you type “gem which rspec” you’ll see the path where exactly Rspec has been downloaded. It’s outside your project, and it is understandable, because you might want to use it in other project on the same computer.
“rspec --help” says that we need to “rspec --init” to initialize the project:
$ rspec --init
create .rspec
create spec/spec_helper.rb
We have two more files, “.rspec” and “spec_helper.rb”, and one “spec” directory. Simply put, “spec” is specification, or “test”. Developers often use words “spec” and “test” interchangeably.
”.spec_helper.rb” is quite lengthy, about one hundred lines, but it is mostly comments. It’s auxiliary file that aims to provide a way to tune Rspec to your needs. We’ll skip doing any adjustments for now. Look at the file structure of our newly created project:
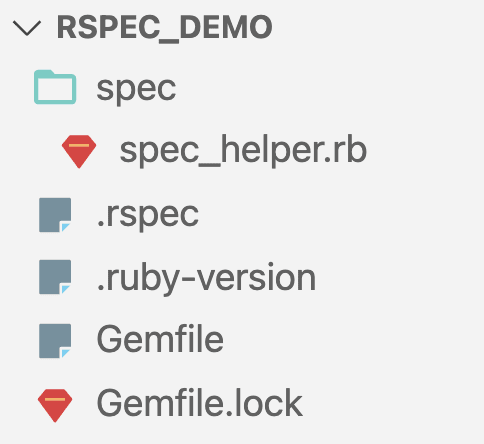
Whoa, we haven’t done anything yet, and we’ve gotten five files, including two dot-files! We have one snake case file (snake_case, where words delimiter is underscore), and one kebab case file (kebab-case, where words delimiter is dash). We have files with extension, and files without extension. Well, the world is not perfect, and the world of software development is never perfect. There are always trade offs and imperfections.
It’s time to write something meaningful now and covering it with tests. And here we have to add a note about important question: what do you do first?
- Do you write tests first? (TDD, Test Driven Development)
- Or do you write code first?
The answer is not easy. There were many controversial debates about what is actually better. In our case we already have some code, so we’ll start with writing code first:
def total_weight(options={})
a = options[:soccer_ball_count] || 0
b = options[:tennis_ball_count] || 0
c = options[:golf_ball_count] || 0
(a * 410) + (b * 58) + (c * 45) + 29
end
x = total_weight(soccer_ball_count: 3, tennis_ball_count: 2, golf_ball_count: 1)
It’s example from previous chapters where we calculate order shipping weight. We just do basic multiplications above, like multiplying the number of soccer balls (“a” variable) by the weight of one soccer ball in grams (410), adding it to the weights of tennis balls, and golf balls. And the 29 is the weight of a shipping box.
Method works perfectly fine, but why do we want to cover the method with tests? To answer this question, let’s try to imagine what could go wrong here.
First, it is about money. Code should be reliable when it comes to calculating costs. A programmer, in a year or two, might want to improve the code by adding new features. For example, adding support for baseball balls. It would be nice if we keep things under control and have ability at least to run the method and compare result with expectations.
Second, somebody can decide that “|| 0” is redundant. It can be true, because the following code works okay (try to run it):
def total_weight(options={})
a = options[:soccer_ball_count]
b = options[:tennis_ball_count]
c = options[:golf_ball_count]
(a * 410) + (b * 58) + (c * 45) + 29
end
x = total_weight(soccer_ball_count: 3, tennis_ball_count: 2, golf_ball_count: 1)
But it works only when you specify all parameters to “total_weight” function. When you omit the parameter, the code throws an exception:
$ pry
...
x = total_weight(soccer_ball_count: 3, tennis_ball_count: 2)
NoMethodError: undefined method `*' for nil:NilClass
from (pry):12:in `total_weight'
A good test will prevent this error.
Third, imagine a more sophisticated scenario. Like if the total weight is more than a certain threshold, we might need a different kind of box. Or two boxes. Or we want to add a gift weight once we have two or more tennis balls in the cart.
With limited resources (say you only have one hour while coding on a train), you can skip test files and just test the method manually with Pry. But will you agree that sharing your code is better when you have a test that checks that the code works fine, so anyone can run all tests with one single command and ensure everything is in place!
We’ll create “lib” directory and two files “shipment.rb” and “app.rb” the following way:
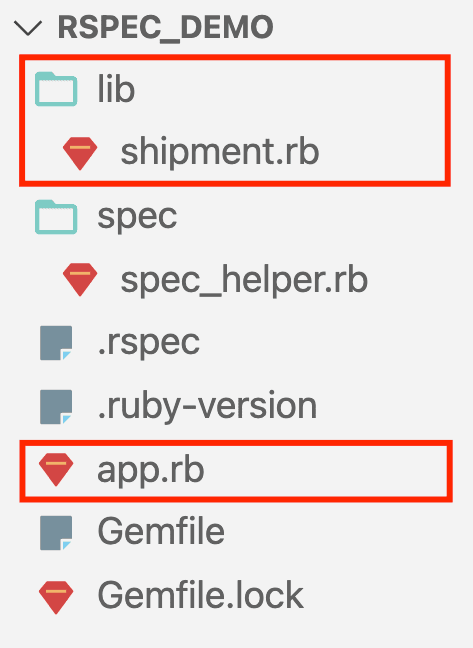
Here is the “app.rb”:
require './lib/shipment'
x = Shipment.total_weight(soccer_ball_count: 3, tennis_ball_count: 2, golf_ball_count: 1)
puts x
“lib/shipment.rb” has the method we discussed above plus the module wrapper:
module Shipment
module_function
def total_weight(options={})
a = options[:soccer_ball_count] || 0
b = options[:tennis_ball_count] || 0
c = options[:golf_ball_count] || 0
(a * 410) + (b * 58) + (c * 45) + 29
end
end
The similar way we could have created a class instead of a module, and define the method as “def self.totalweight”, but it’s not recommended to create a class without intent to create its instance.
Once you run “app.rb”, you’ll see the total shipping weight:
$ ruby app.rb
1420
So we’ve split the program into two units:
- The actual logic in “
shipment.rb” (should be tested) - And the entry point in “
app.rb” (untested, and it’s okay)
We’ll create a test for the first unit. Add “shipment_spec.rb” to the “spec” directory:
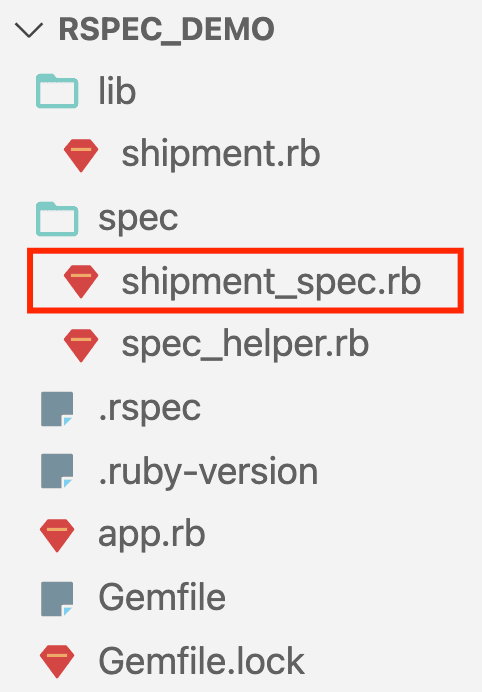
With the following code:
require './lib/shipment'
describe Shipment do
it 'should work without options' do
expect(Shipment.total_weight).to eq(29)
end
end
And run tests with “rspec” command. Below we use “d” (documentation) format option, so the output is more verbose:
$ rspec -f d
Shipment
should work without options
Finished in 0.00154 seconds (files took 0.09464 seconds to load)
1 example, 0 failures
It says “1 example, 0 failures”, great result, you did it! Was it your first Rspec test?
But what was this Rspec weird syntax about? Let’s look closer:
# Require the unit, so we have something to test
require './lib/shipment'
# Describing "Shipment" within a block, letting Rspec know
# that we're going to test "Shipment" class or module
describe Shipment do
# Syntax to say almost in plain English:
# "It should work without options"
# "it" is Rspec keyword (DSL) that accepts block
it 'should work without options' do
# Syntax to say almost in plain English:
# "Expect shipment total weight to equal 29"
expect(Shipment.total_weight).to eq(29)
end
end
The code looks a little bit magical and friendly at the same time. We were using plain English instructions, like “it should work”, “expect shipment total weight to equal…”.
We will add one more test to our test suite:
require './lib/shipment'
describe Shipment do
it 'should work without options' do
expect(Shipment.total_weight).to eq(29)
end
it 'should calculate shipment with only one item' do
expect(Shipment.total_weight(soccer_ball_count: 1)).to eq(439)
expect(Shipment.total_weight(tennis_ball_count: 1)).to eq(87)
expect(Shipment.total_weight(golf_ball_count: 1)).to eq(74)
end
end
Result:
$ rspec -f d
Shipment
should work without options
should calculate shipment with only one item
Finished in 0.00156 seconds (files took 0.09641 seconds to load)
2 examples, 0 failures
The second test checks executes the code and checks the outcome to equal to certain values plus shipping cost. Readability can be slightly improved if we specify the final numbers the following way:
expect(Shipment.total_weight(soccer_ball_count: 1)).to eq(410 + 29)
expect(Shipment.total_weight(tennis_ball_count: 1)).to eq(58 + 29)
expect(Shipment.total_weight(golf_ball_count: 1)).to eq(45 + 29)
You might have already noticed the pattern here:
expect(something).to eq(some_value)
which can be written with “be” keyword as well:
expect(something).to be(some_value)
We gonna cover difference between “eq” and “be” in a bit. The pattern itself looks like a plain English sentence: “Son, when you go to school, I expect you to be a good boy”. Rspec DSL for this english sentence would look like:
expect(son).to be(a_good_boy)
or
expect(son).not_to be(a_bad_boy)
Without Rspec DSL the program might look like:
if son != a_good_boy
panic
end
But Rspec provides the way to represent it in a more elegant (from Rspec point of view) way. There is, of course, “if...else” statement under the hood. But in tests we use more declarative way of writing code, we express our expectations, we don’t say “if”, “then”, “else”, and so on. So mommy doesn’t tell what to do (“listen to the teacher”, “don’t fight”), she sets expectations (“be a good boy”). In other words, spec is specification that the code needs to follow.
Expressions like “expect(son).to” and “expect(son).not_to” are expectations, and “eq(...)” and “be(...)” are matchers. There are quite a few matchers for Rspec. Expectations might look like in-place expressions or code blocks.
Examples of expectations with expressions:
expect(son).to be(a_good_boy)
expect(soccer_ball_weight).to eq(410)
expect(Shipment.total_weight(soccer_ball_count: 1)).to eq(439)
Expressions are:
sonsoccer_ball_weightShipment.total_weight(soccer_ball_count: 1)
Blocks are used together with corresponding matchers. The benefits of providing a block is that code execution is not happening right away and feed the result to Rspec for comparison. We feed the block to Rspec -the code that can be executed. Rspec decides when to execute this code. This approach is little bit more flexible, because Rspec can execute code and measure something.
Imagine you want to test a water bucket. One way of testing it is to compare the reading at the bottom to the value you expect. Another way to test it is to fill the bucket with the certain amount of water to check if the bucket handle works as expected and it is not loose.
This syntax in Rspec looks little bit clunky:
expect { Shipment.total_weight(ford_trucks: 100) }.to raise_error
expect { some_order.add(item) }.to change { order.item_count }.by(1)
Blocks are:
{ Shipment.total_weight(ford_trucks: 100) }{ some_order.add(item) }
And matchers are:
raise_errorchange { order.item_count }.by(1)(yes, matcher actually accepts another block and does method chaining after that)
Good news is that it is pretty much the most complicated part about Rspec. Looking at how others test their code often helps. So we encourage you to look at how your team mates do their Rspec expectations and ask questions! Also, the full list of built-in matchers looks like something worth looking at.
In this chapter we won’t be able to cover all Rspec aspects, but knowing the difference between “eq” and “be” is important.
“Be” means “to be exactly this”. While “eq” means “equal to, you don’t have to be exactly this, just equal is fine”.
For example, “Om” sign tattoos are all equal, but not exactly the same.
Someone would say:
expect(boyfriend_tattoo).to eq(:om_sign)
But not:
expect(boyfriend_tattoo).to be(om_sign)
However, if someone is missing, the expectation can be used with “be” keyword:
expect(missing_person_tattoo).to be(om_sign)
Because in this case we compare tattoo to the actual photo of the tattoo we have.
Same with Ruby objects. Everything is an object in Ruby. There can be equal “a” and “b” variables, but these can be independent objects located in different parts of computer memory:
$ pry
> a = "XXX"
> b = "XXX"
> a == b
=> true
> a.__id__ == b.__id__
=> false
Let’s add one more test case for our Ruby program:
it 'should calculate shipment with multiple items' do
expect(
Shipment.total_weight(soccer_ball_count: 3, tennis_ball_count: 2, golf_ball_count: 1)
).to eq(1420)
end
(There is no any code blocks here, only expression because we’ve just added some new lines for readability)
Result:
$ rspec -f d
Shipment
should work without options
should calculate shipment with only one item
should calculate shipment with multiple items
Finished in 0.00291 seconds (files took 0.19016 seconds to load)
3 examples, 0 failures
It all works fine. Note that we were only dealing with a static method above. Once you have object(s) to test, it will get more interesting!
It’s impossible to cover Rspec with one chapter, but there are few good books out there (for example, Everyday Rspec). The best advice we can give is to think about how would you test the code as you write it.
Exercise 1 Change 1420 above to 1421, run tests and see what happens.
Exercise 2 Your fellow programmer has changed the function so now it raises an exception if you provide no parameters to the method:
module Shipment
module_function
def total_weight(options={})
raise "Can't calculate weight with empty options" if options.empty?
a = options[:soccer_ball_count] || 0
b = options[:tennis_ball_count] || 0
c = options[:golf_ball_count] || 0
(a * 410) + (b * 58) + (c * 45) + 29
end
end
Add a test that passes no options to “total_weight” method and checks if exception gets raised.